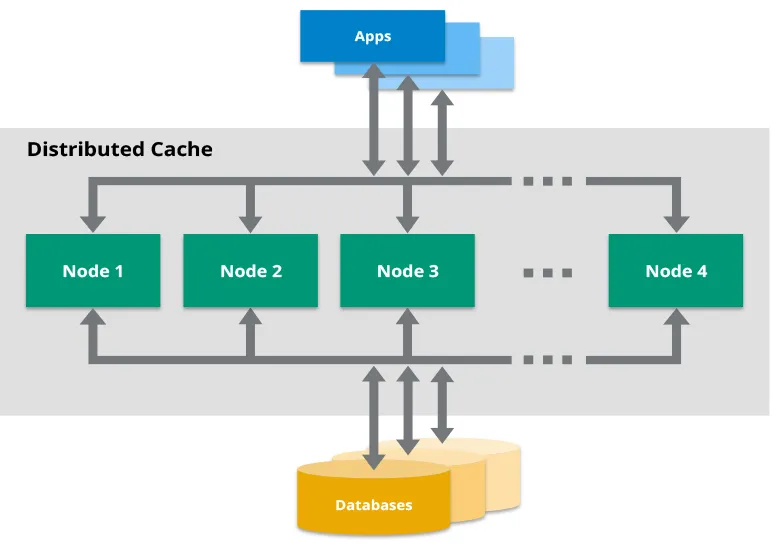
Pourquoi Hazelcast ? Et pourquoi cela devrait vous intéresser ?
Avant de plonger dans les détails, abordons la question principale : Pourquoi Hazelcast ? Dans l'immense océan des solutions de mise en cache, Hazelcast se distingue comme une grille de données en mémoire distribuée qui s'intègre parfaitement avec Java. C'est comme Redis, mais avec une approche Java en priorité et des fonctionnalités astucieuses qui facilitent la mise en cache distribuée dans les microservices.
Voici un aperçu rapide des raisons pour lesquelles Hazelcast pourrait devenir votre nouvel allié :
- API Java native (fini les problèmes de sérialisation)
- Calculs distribués (pensez à MapReduce, mais en plus simple)
- Protection intégrée contre les partitions réseau (parce que ça arrive)
- Évolutivité facile (il suffit d'ajouter des nœuds)
Configurer Hazelcast dans vos microservices
Commençons par les bases. Ajouter Hazelcast à votre microservice Java est étonnamment simple. Tout d'abord, ajoutez la dépendance à votre pom.xml :
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.1.1</version>
</dependency>
Maintenant, créons une instance simple de Hazelcast :
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class CacheConfig {
public HazelcastInstance hazelcastInstance() {
return Hazelcast.newHazelcastInstance();
}
}
Voilà ! Vous avez maintenant un nœud Hazelcast fonctionnant dans votre microservice. Mais attendez, ce n'est pas tout !
Modèles de mise en cache avancés
Maintenant que nous avons couvert les bases, explorons quelques modèles de mise en cache avancés qui feront chanter vos microservices.
1. Mise en cache Read-Through/Write-Through
Ce modèle est comme avoir un assistant personnel pour vos données. Au lieu de gérer manuellement ce qui entre et sort du cache, Hazelcast peut le faire pour vous.
public class UserCacheStore implements MapStore<String, User> {
@Override
public User load(String key) {
// Charger depuis la base de données
}
@Override
public void store(String key, User value) {
// Stocker dans la base de données
}
// Autres méthodes...
}
MapConfig mapConfig = new MapConfig("users");
mapConfig.setMapStoreConfig(new MapStoreConfig().setImplementation(new UserCacheStore()));
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Avec cette configuration, Hazelcast chargera automatiquement les données de votre base de données lorsqu'elles ne sont pas dans le cache, et écrira les données dans la base de données lorsqu'elles sont mises à jour dans le cache. C'est comme de la magie, mais en mieux, car c'est simplement une bonne ingénierie.
2. Modèle de cache proche
Parfois, vous avez besoin que les données soient ultra-rapides, même dans un environnement distribué. Voici le modèle de cache proche. C'est comme avoir un cache pour votre cache. Métaphorique, non ?
NearCacheConfig nearCacheConfig = new NearCacheConfig();
nearCacheConfig.setName("users");
nearCacheConfig.setTimeToLiveSeconds(300);
MapConfig mapConfig = new MapConfig("users");
mapConfig.setNearCacheConfig(nearCacheConfig);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Cette configuration crée un cache local sur chaque nœud Hazelcast, réduisant les appels réseau et accélérant les opérations de lecture. C'est particulièrement utile pour les données fréquemment lues mais rarement mises à jour.
3. Politiques d'éviction
La mémoire est précieuse, surtout dans les microservices. Hazelcast propose des politiques d'éviction sophistiquées pour s'assurer que votre cache ne devienne pas un gouffre de mémoire.
MapConfig mapConfig = new MapConfig("users");
mapConfig.setEvictionConfig(
new EvictionConfig()
.setEvictionPolicy(EvictionPolicy.LRU)
.setMaxSizePolicy(MaxSizePolicy.PER_NODE)
.setSize(10000)
);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Cette configuration met en place une politique d'éviction LRU (Least Recently Used), garantissant que votre cache reste dans une limite de 10 000 entrées par nœud. C'est comme avoir un videur pour votre fête de données, expulsant les entrées les moins populaires lorsque les choses deviennent trop encombrées.
Calculs distribués : Passer au niveau supérieur
La mise en cache est géniale, mais Hazelcast peut faire plus. Voyons comment nous pouvons tirer parti des calculs distribués pour booster nos microservices.
1. Service d'exécution distribué
Besoin d'exécuter une tâche sur l'ensemble de votre cluster ? Le service d'exécution distribué de Hazelcast est là pour vous.
public class UserAnalytics implements Callable<Map<String, Integer>>, HazelcastInstanceAware {
private transient HazelcastInstance hazelcastInstance;
@Override
public Map<String, Integer> call() {
IMap<String, User> users = hazelcastInstance.getMap("users");
// Effectuer des analyses sur les données locales
return results;
}
@Override
public void setHazelcastInstance(HazelcastInstance hazelcastInstance) {
this.hazelcastInstance = hazelcastInstance;
}
}
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IExecutorService executorService = hz.getExecutorService("analytics-executor");
Set<Member> members = hz.getCluster().getMembers();
Map<Member, Future<Map<String, Integer>>> results = executorService.submitToMembers(new UserAnalytics(), members);
// Agréger les résultats
Map<String, Integer> finalResults = new HashMap<>();
for (Future<Map<String, Integer>> future : results.values()) {
Map<String, Integer> result = future.get();
// Fusionner le résultat dans finalResults
}
Ce modèle vous permet d'exécuter des calculs sur les données là où elles se trouvent, réduisant ainsi le mouvement des données et améliorant les performances. C'est comme amener la fonction aux données, au lieu de l'inverse.
2. Processeurs d'entrée
Besoin de mettre à jour plusieurs entrées dans votre cache de manière atomique ? Les processeurs d'entrée sont vos amis.
public class UserUpgradeEntryProcessor implements EntryProcessor<String, User, Object> {
@Override
public Object process(Map.Entry<String, User> entry) {
User user = entry.getValue();
if (user.getPoints() > 1000) {
user.setStatus("GOLD");
entry.setValue(user);
}
return null;
}
}
IMap<String, User> users = hz.getMap("users");
users.executeOnEntries(new UserUpgradeEntryProcessor());
Ce modèle vous permet d'effectuer des opérations sur plusieurs entrées sans avoir besoin de verrouillage explicite ou de gestion de transaction. C'est comme avoir une mini-transaction pour chaque entrée dans votre cache.
Pièges à éviter
Comme tout outil puissant, Hazelcast a ses propres pièges potentiels. Voici quelques-uns à garder à l'esprit :
- Sur-caching : Tout n'a pas besoin d'être mis en cache. Soyez sélectif sur ce que vous mettez dans Hazelcast.
- Ignorer la sérialisation : Hazelcast doit sérialiser les objets. Assurez-vous que vos objets sont sérialisables et envisagez des sérialiseurs personnalisés pour les objets complexes.
- Négliger la surveillance : Mettez en place une surveillance adéquate pour votre cluster Hazelcast. Des outils comme Hazelcast Management Center peuvent être inestimables.
- Oublier la cohérence : Dans un système distribué, la cohérence éventuelle est souvent la norme. Concevez votre application en conséquence.
Conclusion
Nous avons couvert beaucoup de terrain, de la configuration de base aux modèles de mise en cache avancés et aux calculs distribués. Hazelcast est un outil puissant qui peut considérablement améliorer les performances et l'évolutivité de vos microservices Java. Mais rappelez-vous, avec un grand pouvoir vient une grande responsabilité. Utilisez ces modèles judicieusement et considérez toujours les besoins spécifiques de votre application.
Maintenant, allez-y et mettez en cache comme un pro ! Vos microservices (et vos utilisateurs) vous remercieront.
"Le meilleur accès aux données est celui que vous n'avez pas besoin de faire du tout." - Un gourou du cache inconnu (probablement)
Pour aller plus loin
Si vous en voulez plus, consultez ces ressources :
- Dépôt GitHub de Hazelcast
- Livre blanc sur les stratégies de mise en cache de Hazelcast
- Documentation Hazelcast
Bonne mise en cache !