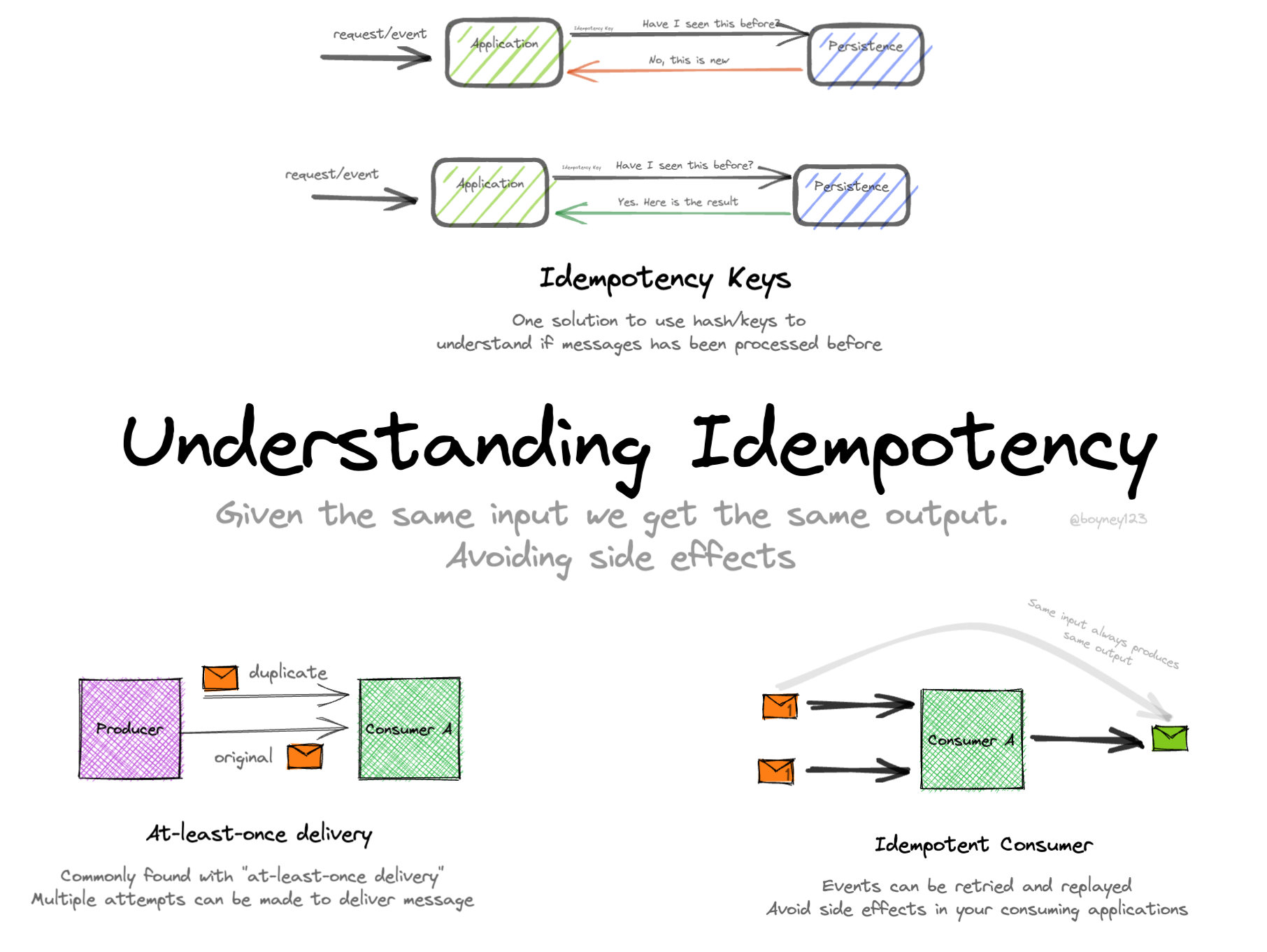
TL;DR : L'idempotence est votre nouvelle meilleure amie
L'idempotence garantit qu'une opération, lorsqu'elle est répétée, ne modifie pas l'état du système au-delà de l'application initiale. C'est crucial pour maintenir la cohérence dans les systèmes distribués, surtout lorsqu'il s'agit de problèmes de réseau, de tentatives de réessai et de requêtes concurrentes. Nous aborderons :
- APIs REST idempotentes : Parce qu'une commande vaut mieux que cinq identiques
- Idempotence des consommateurs Kafka : Assurez-vous que vos messages sont traités une seule fois
- Files de tâches distribuées : Assurez-vous que vos travailleurs collaborent harmonieusement
APIs REST idempotentes : Une commande pour les gouverner toutes
Commençons par les APIs REST, l'élément de base des systèmes backend modernes. Mettre en œuvre l'idempotence ici est crucial, surtout pour les opérations qui modifient l'état.
Le modèle de clé d'idempotence
Une technique efficace consiste à utiliser une clé d'idempotence. Voici comment cela fonctionne :
- Le client génère une clé d'idempotence unique pour chaque requête.
- Le serveur stocke cette clé avec la réponse de la première requête réussie.
- Pour les requêtes suivantes avec la même clé, le serveur renvoie la réponse stockée.
Voici un exemple rapide en Python avec Flask :
from flask import Flask, request, jsonify
import redis
app = Flask(__name__)
redis_client = redis.Redis(host='localhost', port=6379, db=0)
@app.route('/api/order', methods=['POST'])
def create_order():
idempotency_key = request.headers.get('Idempotency-Key')
if not idempotency_key:
return jsonify({"error": "Idempotency-Key header is required"}), 400
# Vérifiez si nous avons déjà vu cette clé
cached_response = redis_client.get(idempotency_key)
if cached_response:
return jsonify(eval(cached_response)), 200
# Traitez la commande
order = process_order(request.json)
# Stockez la réponse
redis_client.set(idempotency_key, str(order), ex=3600) # Expire après 1 heure
return jsonify(order), 201
def process_order(order_data):
# Votre logique de traitement de commande ici
return {"order_id": "12345", "status": "created"}
if __name__ == '__main__':
app.run(debug=True)
Attention : Génération et expiration des clés
Bien que le modèle de clé d'idempotence soit puissant, il présente ses propres défis :
- Génération de clés : Assurez-vous que les clients génèrent des clés vraiment uniques. UUID4 est un bon choix, mais n'oubliez pas de gérer les collisions potentielles (bien que rares).
- Expiration des clés : Ne gardez pas ces clés pour toujours ! Définissez un TTL approprié en fonction des besoins de votre système.
- Évolutivité du stockage : À mesure que votre système grandit, votre stockage de clés aussi. Planifiez cela dans votre infrastructure.
"Avec une grande idempotence vient une grande responsabilité... et beaucoup de gestion de clés."
Idempotence des consommateurs Kafka : Maîtriser le flux
Ah, Kafka ! La plateforme de streaming distribuée qui est soit votre meilleure amie, soit votre pire cauchemar, selon la façon dont vous gérez l'idempotence.
Les sémantiques "exactement une fois"
Kafka 0.11.0 a introduit le concept de sémantiques "exactement une fois", ce qui change la donne pour les consommateurs idempotents. Voici comment en tirer parti :
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("enable.idempotence", true);
props.put("acks", "all");
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", 5);
Producer producer = new KafkaProducer<>(props);
Mais attendez, il y a plus ! Pour vraiment atteindre l'idempotence, vous devez également considérer votre logique de consommateur :
@KafkaListener(topics = "orders")
public void listen(ConsumerRecord record) {
String orderId = record.key();
String orderDetails = record.value();
// Vérifiez si nous avons déjà traité cette commande
if (orderRepository.existsById(orderId)) {
log.info("Order {} already processed, skipping", orderId);
return;
}
// Traitez la commande
Order order = processOrder(orderDetails);
orderRepository.save(order);
}
Attention : Le dilemme de la déduplication
Bien que les sémantiques "exactement une fois" de Kafka soient puissantes, elles ne sont pas une solution miracle :
- Fenêtre de déduplication : Combien de temps gardez-vous la trace des messages traités ? Trop court, et vous risquez des doublons. Trop long, et votre stockage explose.
- Garanties d'ordre : Assurez-vous que votre déduplication ne casse pas les sémantiques d'ordre des messages là où c'est important.
- Traitement avec état : Pour des opérations complexes avec état, envisagez d'utiliser Kafka Streams avec ses magasins d'état intégrés pour une idempotence plus robuste.
Files de tâches distribuées : Quand les travailleurs doivent bien s'entendre
Les files de tâches distribuées comme Celery ou Bull sont fantastiques pour décharger le travail, mais elles peuvent être un cauchemar si elles ne sont pas gérées de manière idempotente. Voyons quelques stratégies pour garder vos travailleurs sous contrôle.
Le modèle "Vérifier puis agir"
Ce modèle consiste à vérifier si une tâche a été complétée avant de l'exécuter réellement. Voici un exemple avec Celery :
from celery import Celery
from myapp.models import Order
app = Celery('tasks', broker='redis://localhost:6379')
@app.task(bind=True, max_retries=3)
def process_order(self, order_id):
try:
order = Order.objects.get(id=order_id)
# Vérifiez si la commande a déjà été traitée
if order.status == 'processed':
return f"Order {order_id} already processed"
# Traitez la commande
result = do_order_processing(order)
order.status = 'processed'
order.save()
return result
except Exception as exc:
self.retry(exc=exc, countdown=60) # Réessayer après 1 minute
def do_order_processing(order):
# Votre logique de traitement de commande ici
pass
Attention : Conditions de concurrence et échecs partiels
Le modèle "Vérifier puis agir" n'est pas sans défis :
- Conditions de concurrence : Dans des scénarios de haute concurrence, plusieurs travailleurs peuvent passer la vérification simultanément. Envisagez d'utiliser des verrous de base de données ou des verrous distribués (par exemple, basés sur Redis) pour les sections critiques.
- Échecs partiels : Que se passe-t-il si votre tâche échoue à mi-chemin ? Concevez vos tâches pour qu'elles soient soit entièrement complétées, soit entièrement annulables.
- Jetons d'idempotence : Pour des scénarios plus complexes, envisagez de mettre en œuvre un système de jetons d'idempotence similaire au modèle d'API REST que nous avons discuté plus tôt.
Le coin philosophique : Pourquoi tout ce remue-ménage ?
Vous vous demandez peut-être : "Pourquoi se donner tout ce mal ? Ne pouvons-nous pas simplement espérer le meilleur ?" Eh bien, mon ami, dans le monde des systèmes distribués, l'espoir n'est pas une stratégie. L'idempotence est cruciale parce que :
- Elle assure la cohérence des données dans votre système.
- Elle rend votre système plus résilient aux problèmes de réseau et aux réessais.
- Elle simplifie la gestion des erreurs et le débogage.
- Elle permet une mise à l'échelle et une maintenance plus faciles de votre architecture distribuée.
"Dans les systèmes distribués, l'idempotence n'est pas juste un atout ; c'est la différence entre un système qui gère les échecs avec grâce et un qui devient un chaos plus vite que vous ne pouvez dire 'partition réseau'."
Conclusion : Votre boîte à outils d'idempotence
Comme nous l'avons vu, mettre en œuvre l'idempotence dans les systèmes backend distribués n'est pas une mince affaire, mais c'est absolument crucial pour construire des applications robustes et évolutives. Voici votre boîte à outils d'idempotence à emporter :
- Pour les APIs REST : Utilisez des clés d'idempotence et une gestion prudente des requêtes.
- Pour les consommateurs Kafka : Exploitez les sémantiques "exactement une fois" et mettez en œuvre une déduplication intelligente.
- Pour les files de tâches distribuées : Employez le modèle "Vérifier puis agir" et méfiez-vous des conditions de concurrence.
Rappelez-vous, l'idempotence n'est pas juste une fonctionnalité ; c'est un état d'esprit. Commencez à y penser dès la phase de conception de votre système, et vous vous en remercierez plus tard lorsque vos services continueront de fonctionner sans accroc, même face aux problèmes de réseau, aux redémarrages de service et à ces redoutables problèmes de production à 3 heures du matin.
Allez maintenant, et rendez vos systèmes distribués idempotents ! Votre futur vous (et votre équipe d'exploitation) vous en remerciera.
Pour aller plus loin
- Sémantiques "exactement une fois" dans Apache Kafka
- Guide de l'idempotence des tâches Celery
- Approche de Stripe sur l'idempotence
Bon codage, et que vos systèmes soient toujours cohérents !