Résumé
Implémenter des consommateurs idempotents dans Kafka est essentiel pour garantir la cohérence des données et éviter le traitement en double. Nous explorerons les meilleures pratiques, les pièges courants et quelques astuces pour rendre vos consommateurs Kafka aussi idempotents qu'une fonction mathématique.
Pourquoi l'Idempotence est Importante
Avant de plonger dans les détails, rappelons rapidement pourquoi l'idempotence est cruciale :
- Évite le traitement en double des messages
- Assure la cohérence des données dans votre système
- Vous épargne des sessions de débogage nocturnes et des frustrations
- Rend votre système plus résilient face aux échecs et aux tentatives de réessai
Maintenant que nous sommes tous sur la même longueur d'onde, passons aux choses sérieuses !
Meilleures Pratiques pour Implémenter des Consommateurs Idempotents
1. Utiliser des Identifiants Uniques pour les Messages
La première règle du Club des Consommateurs Idempotents est : Toujours utiliser des identifiants uniques pour les messages. (La deuxième règle est... vous avez compris l'idée.)
La mise en œuvre est simple :
public class KafkaMessage {
private String id;
private String payload;
// ... autres champs et méthodes
}
public class IdempotentConsumer {
private Set processedMessageIds = new HashSet<>();
public void consume(KafkaMessage message) {
if (processedMessageIds.add(message.getId())) {
// Traiter le message
processMessage(message);
} else {
// Message déjà traité, le sauter
log.info("Message en double ignoré : {}", message.getId());
}
}
}
Astuce : Utilisez des UUIDs ou une combinaison de sujet, partition et offset pour vos identifiants de message. C'est comme donner à chaque message son propre flocon de neige unique !
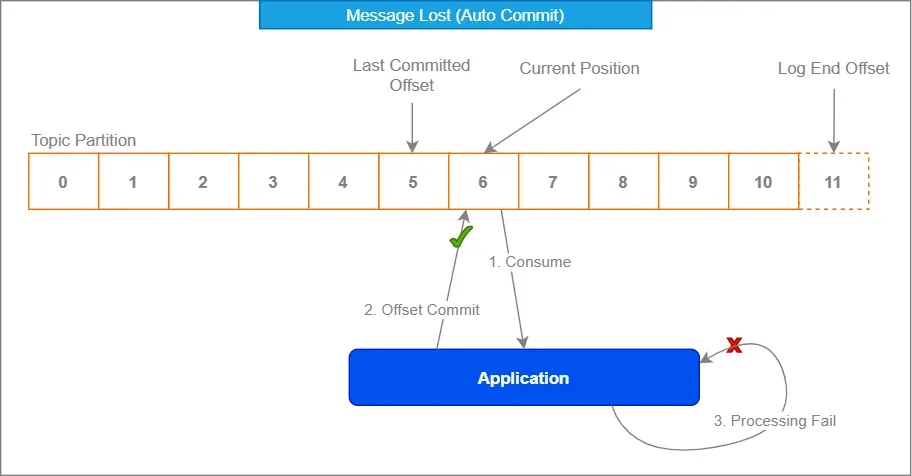
2. Exploiter la Gestion des Offsets de Kafka
La gestion intégrée des offsets de Kafka est votre alliée. Adoptez-la comme cet oncle bizarre lors des réunions de famille – cela peut sembler étrange au début, mais elle vous soutient.
Properties props = new Properties();
props.put("enable.auto.commit", "false");
props.put("isolation.level", "read_committed");
KafkaConsumer consumer = new KafkaConsumer<>(props);
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records) {
processRecord(record);
}
consumer.commitSync();
}
En désactivant l'auto-commit et en validant manuellement les offsets après traitement, vous vous assurez que les messages ne sont marqués comme consommés que lorsque vous êtes sûr à 100% qu'ils ont été traités correctement.
3. Implémenter une Stratégie de Déduplication
Parfois, malgré nos meilleurs efforts, des doublons se faufilent comme des ninjas furtifs. C'est là qu'une bonne stratégie de déduplication est utile.
Envisagez d'utiliser un cache distribué comme Redis pour stocker les identifiants des messages traités :
@Service
public class DuplicateChecker {
private final RedisTemplate redisTemplate;
public DuplicateChecker(RedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
public boolean isDuplicate(String messageId) {
return !redisTemplate.opsForValue().setIfAbsent(messageId, "processed", Duration.ofDays(1));
}
}
Cette approche vous permet de vérifier les doublons sur plusieurs instances de consommateurs et même après des redémarrages. C'est comme avoir un videur pour vos messages – "Si votre ID n'est pas sur la liste, vous n'entrez pas !"
4. Utiliser des Opérations Idempotentes
Dans la mesure du possible, concevez vos opérations de traitement de messages pour qu'elles soient naturellement idempotentes. Cela signifie que même si un message est traité plusieurs fois, cela n'affectera pas le résultat final.
Par exemple, au lieu de :
public void incrementCounter(String counterId) {
int currentValue = counterRepository.get(counterId);
counterRepository.set(counterId, currentValue + 1);
}
Envisagez d'utiliser une opération atomique :
public void incrementCounter(String counterId) {
counterRepository.increment(counterId);
}
De cette façon, même si l'opération d'incrément est appelée plusieurs fois pour le même message, le résultat final sera le même.
Pièges Courants et Comment les Éviter
Maintenant que nous avons couvert les bases, examinons quelques pièges courants dans lesquels même les développeurs expérimentés peuvent tomber :
1. Se Fonder Uniquement sur les Sémantiques "Exactement Une Fois" de Kafka
Bien que Kafka offre des sémantiques "exactement une fois", ce n'est pas une solution miracle. Cela garantit uniquement une livraison exactement une fois au sein du cluster Kafka, pas un traitement de bout en bout exactement une fois dans votre application.
"Faites confiance, mais vérifiez" – Ronald Reagan (parlant probablement des messages Kafka)
Implémentez toujours vos propres vérifications d'idempotence en plus des garanties de Kafka.
2. Ignorer les Limites Transactionnelles
Assurez-vous que le traitement de vos messages et les validations d'offsets font partie de la même transaction. Sinon, vous pourriez vous retrouver dans une situation où vous avez traité un message mais n'avez pas validé l'offset, ce qui entraîne un retraitement au redémarrage du consommateur.
@Transactional
public void processMessage(ConsumerRecord record) {
// Traiter le message
businessLogic.process(record.value());
// Accuser réception manuellement du message
acknowledgment.acknowledge();
}
3. Négliger les Contraintes de Base de Données
Si vous stockez des données traitées dans une base de données, utilisez des contraintes uniques à votre avantage. Elles peuvent agir comme une couche de protection supplémentaire contre les doublons.
CREATE TABLE processed_messages (
message_id VARCHAR(255) PRIMARY KEY,
processed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Ensuite, dans votre code Java :
try {
jdbcTemplate.update("INSERT INTO processed_messages (message_id) VALUES (?)", messageId);
// Traiter le message
} catch (DuplicateKeyException e) {
// Message déjà traité, le sauter
}
Techniques Avancées pour les Courageux
Prêt à passer au niveau supérieur avec vos consommateurs idempotents ? Voici quelques techniques avancées pour les audacieux :
1. Clés d'Idempotence dans les En-têtes
Au lieu de vous fier au contenu du message pour l'idempotence, envisagez d'utiliser les en-têtes des messages Kafka pour stocker les clés d'idempotence. Cela permet un contenu de message plus flexible tout en maintenant l'idempotence.
// Producteur
ProducerRecord record = new ProducerRecord<>("my-topic", "key", "value");
record.headers().add("idempotency-key", UUID.randomUUID().toString().getBytes());
producer.send(record);
// Consommateur
ConsumerRecord record = // ... reçu de Kafka
byte[] idempotencyKeyBytes = record.headers().lastHeader("idempotency-key").value();
String idempotencyKey = new String(idempotencyKeyBytes, StandardCharsets.UTF_8);
2. Déduplication Basée sur le Temps
Dans certains scénarios, vous pourriez vouloir implémenter une déduplication basée sur le temps. Cela est utile lorsque vous traitez des flux d'événements où le même événement peut être légitimement répété après une certaine période.
public class TimeBasedDuplicateChecker {
private final RedisTemplate redisTemplate;
private final Duration deduplicationWindow;
public TimeBasedDuplicateChecker(RedisTemplate redisTemplate, Duration deduplicationWindow) {
this.redisTemplate = redisTemplate;
this.deduplicationWindow = deduplicationWindow;
}
public boolean isDuplicate(String messageId) {
String key = "dedup:" + messageId;
Boolean isNew = redisTemplate.opsForValue().setIfAbsent(key, "processed", deduplicationWindow);
return isNew != null && !isNew;
}
}
3. Agrégations Idempotentes
Lorsque vous traitez des opérations d'agrégation, envisagez d'utiliser des techniques d'agrégation idempotentes. Par exemple, au lieu de stocker une somme en cours, stockez des valeurs individuelles et calculez la somme à la volée :
public class IdempotentAggregator {
private final Map values = new ConcurrentHashMap<>();
public void addValue(String key, double value) {
values.put(key, value);
}
public double getSum() {
return values.values().stream().mapToDouble(Double::doubleValue).sum();
}
}
Cette approche garantit que même si un message est traité plusieurs fois, cela n'affectera pas le résultat final de l'agrégation.
Conclusion
Implémenter des consommateurs idempotents dans Kafka peut sembler une tâche ardue, mais avec ces meilleures pratiques et techniques, vous gérerez les doublons comme un pro en un rien de temps. Rappelez-vous, la clé est de toujours s'attendre à l'inattendu et de concevoir votre système avec l'idempotence à l'esprit dès le départ.
Voici une liste de contrôle rapide à garder à portée de main :
- Utiliser des identifiants uniques pour les messages
- Exploiter la gestion des offsets de Kafka
- Implémenter une stratégie de déduplication robuste
- Concevoir des opérations naturellement idempotentes lorsque c'est possible
- Être conscient des pièges courants et savoir comment les éviter
- Envisager des techniques avancées pour des cas d'utilisation spécifiques
En suivant ces directives, vous améliorerez non seulement la fiabilité et la cohérence de vos systèmes basés sur Kafka, mais vous vous épargnerez également d'innombrables heures de débogage et de maux de tête. Et soyons honnêtes, n'est-ce pas ce que nous recherchons tous ?
Allez maintenant, et conquérissez ces messages en double ! Votre futur vous (et votre équipe d'exploitation) vous remerciera.
"Dans le monde des consommateurs Kafka, l'idempotence n'est pas juste une fonctionnalité – c'est un superpouvoir." – Un développeur avisé (probablement)
Bon codage, et que vos consommateurs soient toujours idempotents !