Nous allons construire un backend qui combine la puissance des modèles de langage avancés (LLM) avec la précision des bases de données vectorielles en utilisant LangChain. Le résultat ? Une API capable de comprendre le contexte, de récupérer des informations pertinentes et de générer des réponses semblables à celles d'un humain en temps réel. Ce n'est pas seulement intelligent ; c'est incroyablement intelligent.
La Révolution RAG : Pourquoi Cela Vous Concerne-t-il ?
Avant de nous retrousser les manches et de commencer à coder, voyons pourquoi RAG suscite tant d'intérêt dans le monde de l'IA :
- Le Contexte est Roi : Les systèmes RAG comprennent et exploitent le contexte mieux que les recherches traditionnelles basées sur des mots-clés.
- Frais et Pertinent : Contrairement aux LLM statiques, RAG peut accéder à des informations à jour.
- Réduction des Hallucinations : En ancrant les réponses dans les données récupérées, RAG aide à réduire ces hallucinations gênantes de l'IA.
- Évolutivité : À mesure que vos données augmentent, les connaissances de votre IA augmentent également sans nécessiter de réentraînement constant.
La Pile Technologique : Nos Armes de Choix
Nous ne partons pas au combat les mains vides. Voici notre arsenal :
- LangChain : Notre couteau suisse pour les opérations LLM (oups, j'ai promis de ne pas utiliser cette expression, n'est-ce pas ?)
- Base de Données Vectorielle : Nous utiliserons Pinecone, mais n'hésitez pas à choisir votre préféré
- LLM : GPT-3.5 ou GPT-4 d'OpenAI (ou tout autre LLM de votre choix)
- FastAPI : Pour construire nos points de terminaison API ultra-rapides
- Python : Parce que, eh bien, c'est Python
Mise en Place du Terrain de Jeu
Tout d'abord, préparons notre environnement. Ouvrez votre terminal et installons les packages nécessaires :
pip install langchain pinecone-client openai fastapi uvicorn
Maintenant, créons une structure de base pour notre application FastAPI :
from fastapi import FastAPI
from langchain import OpenAI, VectorDBQA
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
import pinecone
import os
app = FastAPI()
# Initialiser Pinecone
pinecone.init(api_key=os.getenv("PINECONE_API_KEY"), environment=os.getenv("PINECONE_ENV"))
# Initialiser OpenAI
llm = OpenAI(temperature=0.7)
# Initialiser les embeddings
embeddings = OpenAIEmbeddings()
# Initialiser le magasin de vecteurs Pinecone
index_name = "your-pinecone-index-name"
vectorstore = Pinecone.from_existing_index(index_name, embeddings)
# Initialiser la chaîne de QA
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", vectorstore=vectorstore)
@app.get("/")
async def root():
return {"message": "Bienvenue sur l'API propulsée par RAG !"}
@app.get("/query")
async def query(q: str):
result = qa.run(q)
return {"result": result}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Décryptage : Que se Passe-t-il Ici ?
Analysons ce code comme si c'était une grenouille en cours de biologie au lycée (mais bien plus excitant) :
- Nous configurons FastAPI comme notre framework web.
- La classe
OpenAIde LangChain est notre passerelle vers le LLM. VectorDBQAest la baguette magique qui combine notre base de données vectorielle avec le LLM pour répondre aux questions.- Nous utilisons Pinecone comme notre base de données vectorielle, mais vous pouvez le remplacer par des alternatives comme Weaviate ou Milvus.
- Le point de terminaison
/queryest l'endroit où la magie RAG opère. Il prend une question, la passe à travers notre chaîne de QA et renvoie le résultat.
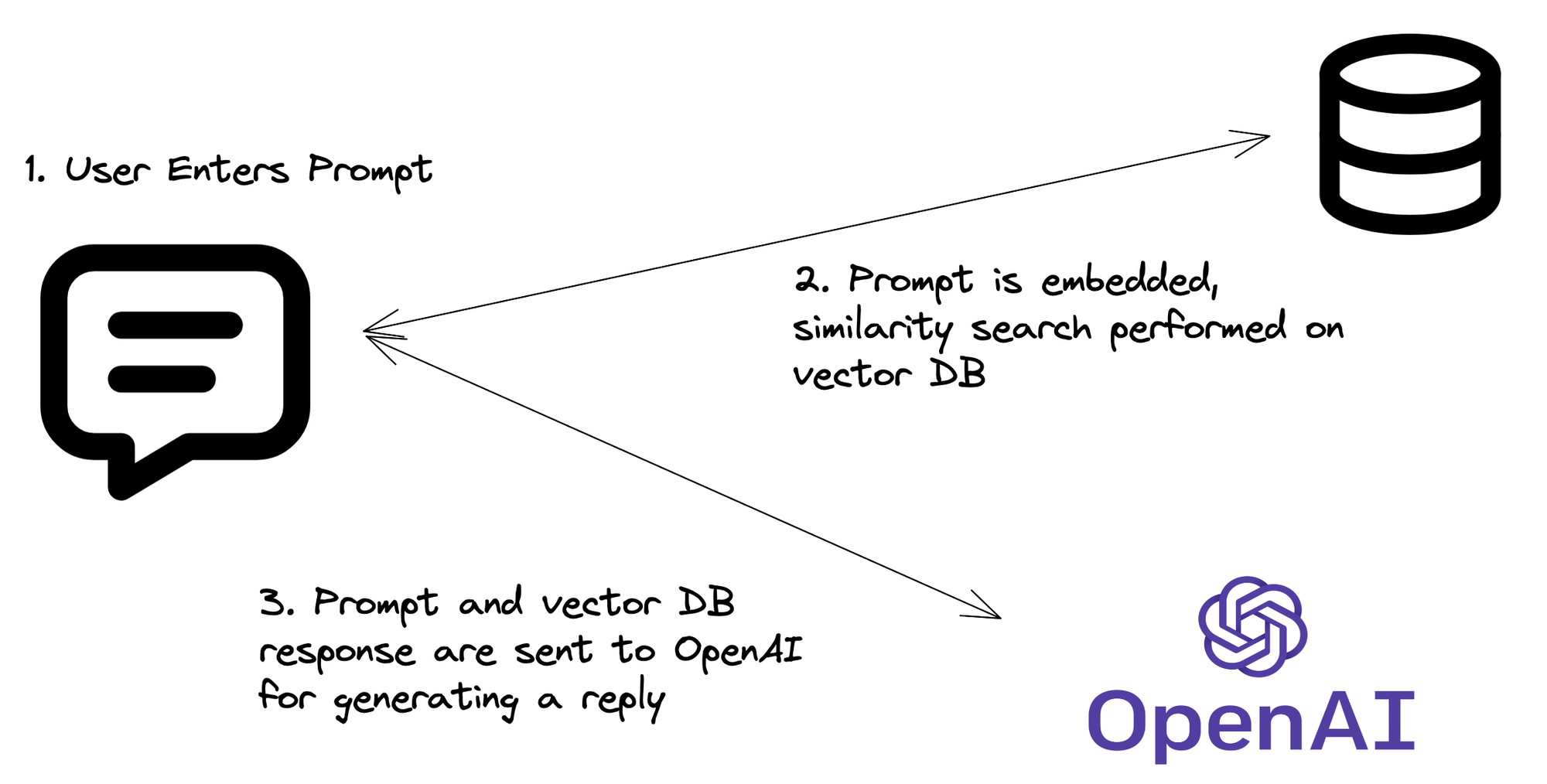
Le Pipeline RAG : Comment Cela Fonctionne Réellement
Maintenant que nous avons le code, décomposons le processus RAG :
- Embedding de la Question : Votre API reçoit une question, qui est ensuite convertie en un embedding vectoriel.
- Recherche Vectorielle : Cet embedding est utilisé pour rechercher dans l'index Pinecone des vecteurs similaires (c'est-à-dire des informations pertinentes).
- Récupération du Contexte : Les documents ou fragments les plus pertinents sont récupérés de Pinecone.
- Magie du LLM : La question originale et le contexte récupéré sont envoyés au LLM.
- Génération de Réponse : Le LLM génère une réponse basée sur la question et le contexte récupéré.
- Retour de l'API : Votre API renvoie cette réponse intelligente et contextuelle.
Booster Votre RAG : Techniques Avancées
Prêt à faire passer votre système RAG de "plutôt cool" à "incroyablement génial" ? Essayez ces techniques avancées :
1. Recherche Hybride
Combinez la recherche vectorielle avec la recherche traditionnelle par mots-clés pour obtenir de meilleurs résultats :
from langchain.retrievers import PineconeHybridSearchRetriever
hybrid_retriever = PineconeHybridSearchRetriever(
embeddings=embeddings,
index=vectorstore.pinecone_index
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=hybrid_retriever)
2. Re-classement
Implémentez une étape de re-classement pour affiner vos documents récupérés :
from langchain.retrievers import RePhraseQueryRetriever
rephraser = RePhraseQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=rephraser)
3. Réponses en Streaming
Pour une expérience plus interactive, diffusez vos réponses API :
from fastapi import FastAPI, Response
from fastapi.responses import StreamingResponse
@app.get("/stream")
async def stream_query(q: str):
async def event_generator():
for token in qa.run(q):
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
Pièges Potentiels : Faites Attention !
Aussi incroyable que soit RAG, il n'est pas sans ses bizarreries. Voici quelques points à surveiller :
- Limitations de la Fenêtre de Contexte : Les LLM ont une taille de contexte maximale. Assurez-vous que vos documents récupérés ne dépassent pas cette limite.
- Pertinence vs. Diversité : Équilibrer les résultats pertinents avec des informations diversifiées peut être délicat. Expérimentez avec vos paramètres de récupération.
- Les Hallucinations n'ont pas Disparu : Bien que RAG réduise les hallucinations, il ne les élimine pas. Implémentez toujours des mécanismes de vérification des faits.
- Coûts de l'API : N'oubliez pas que chaque requête implique potentiellement plusieurs appels API (embedding, recherche vectorielle, LLM). Surveillez vos factures !
Conclusion : Pourquoi Cela Compte
Implémenter RAG dans votre backend ne consiste pas seulement à être à la pointe de la technologie (même si c'est un joli bonus). Il s'agit de créer des applications plus intelligentes et conscientes du contexte, capables de comprendre et de répondre aux requêtes des utilisateurs de manière auparavant impossible.
En combinant les vastes connaissances des LLM avec les informations spécifiques et à jour de votre base de données vectorielle, vous créez un système qui est plus que la somme de ses parties. C'est comme donner à votre API un superpouvoir – la capacité de comprendre, de raisonner et de générer des réponses semblables à celles d'un humain basées sur des données en temps réel.
"Le futur est déjà là – il n'est juste pas réparti de manière égale." - William Gibson
Eh bien, maintenant vous faites partie des chanceux qui ont un morceau de ce futur. Allez de l'avant et construisez des choses incroyables !
Réflexions
En implémentant RAG dans vos projets, considérez ces questions :
- Comment pouvez-vous garantir la confidentialité et la sécurité des données utilisées dans votre système RAG ?
- Quelles considérations éthiques entrent en jeu lors du déploiement d'API alimentées par l'IA ?
- Comment les systèmes RAG pourraient-ils évoluer à mesure que les LLM et les bases de données vectorielles continuent de progresser ?
Les réponses à ces questions façonneront l'avenir des applications alimentées par l'IA. Et maintenant, vous êtes à l'avant-garde de cette révolution. Bon codage !