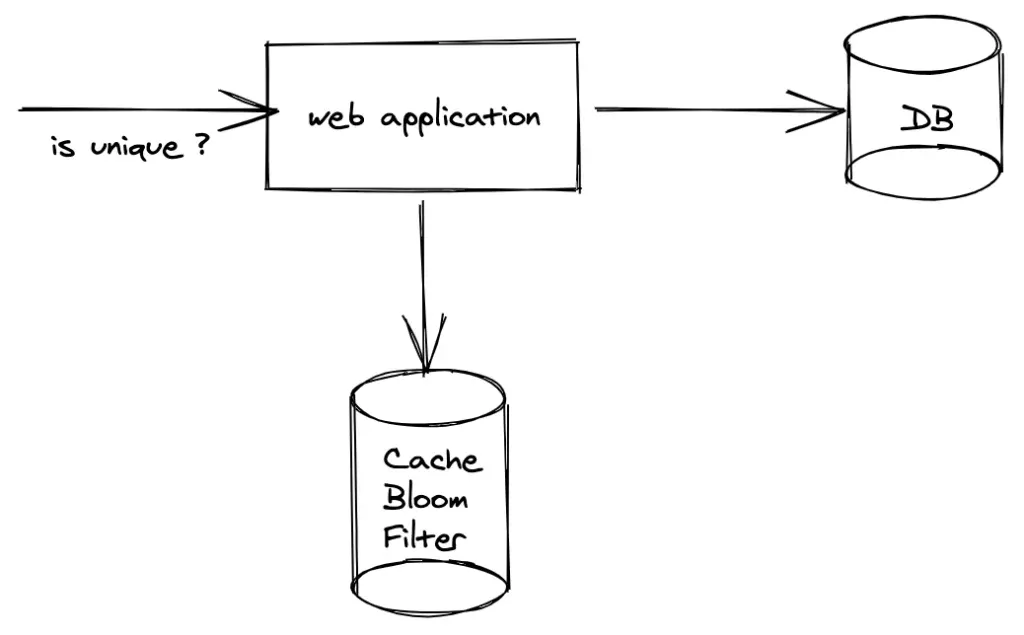
Décomposons ce qu'est réellement un filtre de Bloom :
- Une structure de données probabiliste efficace en termes d'espace
- Utilisée pour tester si un élément appartient à un ensemble
- Peut avoir des faux positifs, mais jamais de faux négatifs
- Parfait pour réduire les recherches inutiles
En termes plus simples, c'est comme un videur pour votre base de données. Il vérifie rapidement si quelque chose pourrait être dans le club (base de données) avant de vous laisser entrer pour regarder autour.
Entrez Redis : L'acolyte rapide
Alors, pourquoi Redis ? Parce qu'il est rapide. Tellement rapide que vous pourriez le manquer en un clin d'œil. Combiner les filtres de Bloom avec Redis, c'est comme attacher une fusée à votre voiture de course déjà rapide.
Configurer votre filtre de Bloom Redis
Tout d'abord, vous devrez installer le module RedisBloom. Si vous utilisez Docker, c'est aussi simple que :
docker run -p 6379:6379 redislabs/rebloom:latestMaintenant, implémentons un filtre de Bloom basique en Python en utilisant la bibliothèque redis-py :
import redis
from redisbloom.client import Client
# Connexion à Redis
rb = Client(host='localhost', port=6379)
# Créer un filtre de Bloom
rb.bfCreate('myfilter', 0.01, 1000000)
# Ajouter quelques éléments
rb.bfAdd('myfilter', 'element1')
rb.bfAdd('myfilter', 'element2')
# Vérifier si les éléments existent
print(rb.bfExists('myfilter', 'element1')) # True
print(rb.bfExists('myfilter', 'element3')) # False
La magie derrière le rideau
Alors, comment cela aide-t-il réellement à réduire les requêtes de base de données ? Décomposons cela :
- Avant de requêter votre base de données, vérifiez le filtre de Bloom
- Si le filtre dit que l'élément n'existe pas, ignorez complètement la requête de base de données
- Si le filtre dit qu'il pourrait exister, procédez à la requête de base de données
Cette vérification simple peut réduire considérablement le nombre de requêtes inutiles, surtout pour les grands ensembles de données avec beaucoup de ratés.
Exemple concret : Authentification utilisateur
Disons que vous construisez un système d'authentification utilisateur. Au lieu de solliciter la base de données pour chaque tentative de connexion avec un nom d'utilisateur inexistant, vous pouvez utiliser un filtre de Bloom pour rejeter rapidement les noms d'utilisateur invalides :
def authenticate_user(username, password):
if not rb.bfExists('users', username):
return "L'utilisateur n'existe pas"
# Ne requêtez la base de données que si le nom d'utilisateur pourrait exister
user = db.get_user(username)
if user and user.check_password(password):
return "Authentification réussie"
else:
return "Identifiants invalides"
Pièges et considérations
Avant de vous lancer dans l'utilisation des filtres de Bloom, gardez ces points à l'esprit :
- Les faux positifs sont possibles, donc votre code doit gérer les échecs de base de données avec grâce
- La taille du filtre est fixe, donc estimez correctement la taille de vos données
- L'ajout d'éléments est unidirectionnel ; vous ne pouvez pas supprimer d'éléments d'un filtre de Bloom
Gains de performance : Montrez-moi les chiffres !
Passons aux choses sérieuses. Dans un scénario de test avec 1 million d'utilisateurs et 10 millions de tentatives de connexion (90 % avec des noms d'utilisateur inexistants) :
- Sans filtre de Bloom : 10 millions de requêtes de base de données
- Avec filtre de Bloom : ~1,9 million de requêtes de base de données (réduction de 81 % !)
Ce n'est pas juste une goutte dans l'océan ; c'est une vague d'efficacité !
Considérations sur l'évolutivité
À mesure que votre application se développe, vous pourriez avoir besoin de penser à :
- Filtres de Bloom distribués sur plusieurs instances Redis
- Reconstruction périodique des filtres pour maintenir la précision
- Surveillance des taux de faux positifs et ajustement des paramètres du filtre
Techniques avancées : Filtres de Bloom comptants
Vous voulez passer au niveau supérieur ? Découvrez les filtres de Bloom comptants. Ils permettent la suppression d'éléments et fournissent des requêtes de comptage approximatives. Voici un exemple rapide :
# Créer un filtre de Bloom comptant
rb.cfCreate('countingfilter', 1000000)
# Ajouter et compter les éléments
rb.cfAdd('countingfilter', 'element1')
rb.cfAdd('countingfilter', 'element1')
rb.cfCount('countingfilter', 'element1') # Retourne 2
Conclusion
Implémenter des filtres de Bloom dans Redis, c'est comme donner à votre base de données une paire de lunettes à rayons X. Elle peut voir à travers le bruit et se concentrer sur ce qui compte vraiment. En réduisant les requêtes inutiles, vous ne faites pas que sauver de la puissance de traitement ; vous créez une expérience plus fluide et plus rapide pour vos utilisateurs.
Rappelez-vous, dans le monde des applications haute performance, chaque milliseconde compte. Alors pourquoi ne pas donner un peu de répit à votre base de données et laisser les filtres de Bloom Redis faire une partie du travail lourd ?
Réflexion
"L'art de programmer est l'art d'organiser la complexité." - Edsger W. Dijkstra
Et parfois, organiser la complexité signifie savoir quand ne pas faire quelque chose. Dans ce cas, ne pas solliciter inutilement la base de données.
Allez maintenant, et utilisez les filtres de Bloom de manière responsable !