Les filtres de Bloom sont comme les videurs du monde des données – ils vous disent rapidement si quelque chose est probablement dans le club (votre ensemble de données) ou définitivement pas, sans réellement ouvrir les portes. Cette structure de données probabiliste peut réduire considérablement les recherches inutiles et les appels réseau, rendant votre système plus rapide et plus efficace.
La Magie Derrière le Rideau
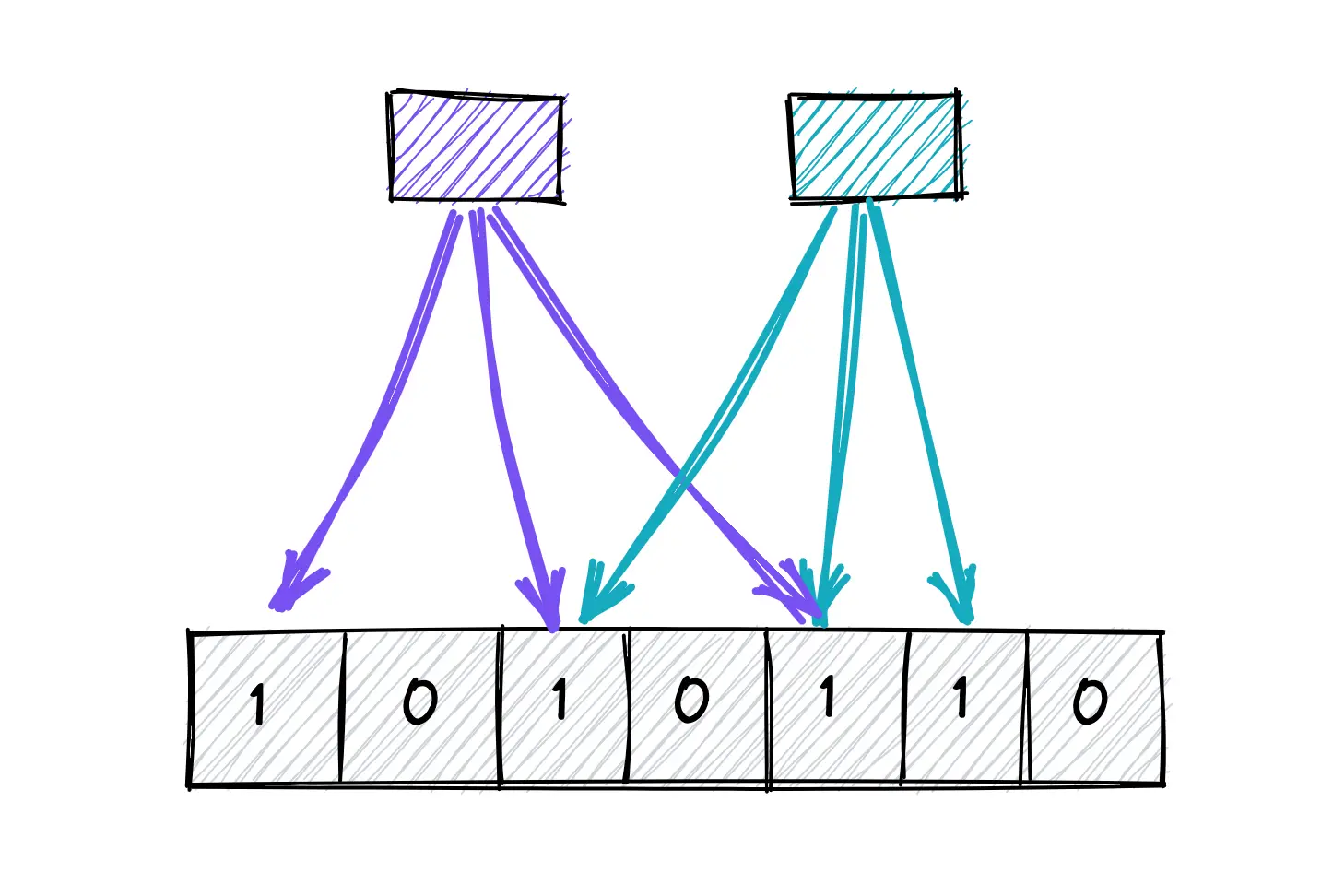
Au cœur, un filtre de Bloom est un tableau de bits. Lorsque vous ajoutez un élément, il est haché plusieurs fois, et les bits correspondants sont mis à 1. Vérifier si un élément existe implique de le hacher à nouveau et de voir si tous les bits correspondants sont définis. C'est simple, mais puissant.
class BloomFilter:
def __init__(self, size, hash_count):
self.size = size
self.hash_count = hash_count
self.bit_array = [0] * size
def add(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
self.bit_array[index] = 1
def check(self, item):
for seed in range(self.hash_count):
index = hash(str(seed) + str(item)) % self.size
if self.bit_array[index] == 0:
return False
return True
Applications Pratiques : Où les Filtres de Bloom Brillent
Explorons quelques scénarios pratiques où les filtres de Bloom peuvent sauver la mise :
1. Systèmes de Cache : Le Gardien
Imaginez que vous gérez un système de cache à grande échelle. Avant d'accéder au stockage principal coûteux, vous pouvez utiliser un filtre de Bloom pour vérifier si la clé pourrait exister dans le cache.
def get_item(key):
if not bloom_filter.check(key):
return None # Définitivement pas dans le cache
# Pourrait être dans le cache, vérifions
return actual_cache.get(key)
Cette simple vérification peut réduire considérablement les échecs de cache et les requêtes inutiles au backend.
2. Optimisation de Recherche : L'Éliminateur Rapide
Dans un système de recherche distribué, les filtres de Bloom peuvent agir comme un pré-filtre pour éliminer les recherches inutiles à travers les fragments.
def search_shards(query):
results = []
for shard in shards:
if shard.bloom_filter.check(query):
results.extend(shard.search(query))
return results
En éliminant rapidement les fragments qui ne contiennent définitivement pas la requête, vous pouvez réduire le trafic réseau et améliorer les temps de recherche.
3. Détection de Duplicata : Le Dédupliqueur Efficace
Lors de l'exploration du web ou du traitement de grands flux de données, détecter rapidement les doublons est crucial.
def process_item(item):
if not bloom_filter.check(item):
bloom_filter.add(item)
process_new_item(item)
else:
# Possiblement déjà vu, faire une vérification supplémentaire
pass
Cette approche peut réduire considérablement l'empreinte mémoire par rapport à la conservation d'une liste complète des éléments traités.
Les Détails : Ajuster Votre Filtre de Bloom
Comme tout bon outil, les filtres de Bloom nécessitent un réglage approprié. Voici quelques considérations clés :
- La taille compte : Plus le filtre est grand, plus le taux de faux positifs est faible, mais plus il utilise de mémoire.
- Fonctions de hachage : Plus de fonctions de hachage réduisent les faux positifs mais augmentent le temps de calcul.
- Nombre d'éléments attendu : Connaître la taille de vos données aide à optimiser les paramètres du filtre.
Voici une formule rapide pour vous aider à dimensionner votre filtre de Bloom :
import math
def optimal_bloom_filter_size(item_count, false_positive_rate):
m = -(item_count * math.log(false_positive_rate)) / (math.log(2)**2)
k = (m / item_count) * math.log(2)
return int(m), int(k)
# Exemple d'utilisation
items = 1000000
fp_rate = 0.01
size, hash_count = optimal_bloom_filter_size(items, fp_rate)
print(f"Taille optimale : {size} bits")
print(f"Nombre optimal de hachages : {hash_count}")
Pièges et Considérations
Avant de vous lancer dans l'utilisation des filtres de Bloom, gardez ces points à l'esprit :
- Les faux positifs existent : Les filtres de Bloom peuvent indiquer qu'un élément pourrait être présent alors qu'il ne l'est pas. Préparez-vous à cela dans votre gestion des erreurs.
- Pas de suppression : Les filtres de Bloom standard ne prennent pas en charge la suppression d'éléments. Consultez les filtres de Bloom comptants si vous avez besoin de cette fonctionnalité.
- Pas une solution miracle : Bien que puissants, les filtres de Bloom ne conviennent pas à tous les scénarios. Évaluez soigneusement votre cas d'utilisation.
"Avec un grand pouvoir vient une grande responsabilité. Utilisez les filtres de Bloom judicieusement, et ils traiteront bien votre backend." - Oncle Ben (s'il était architecte logiciel)
Intégrer les Filtres de Bloom dans Votre Pile
Prêt à essayer les filtres de Bloom ? Voici quelques bibliothèques populaires pour vous aider à démarrer :
- Guava pour les développeurs Java
- pybloom pour les passionnés de Python
- bloomd pour un service réseau autonome
La Vue d'Ensemble : Pourquoi S'en Soucier ?
Dans le grand schéma des choses, les filtres de Bloom sont plus qu'un simple tour astucieux. Ils représentent un principe plus large dans la conception des systèmes : parfois, un peu d'incertitude peut conduire à des gains de performance massifs. En acceptant une petite probabilité de faux positifs, nous pouvons créer des systèmes plus rapides, plus évolutifs et plus efficaces.
Réflexion
En implémentant des filtres de Bloom dans votre architecture, considérez ces questions :
- Comment la nature probabiliste des filtres de Bloom peut-elle influencer d'autres parties de la conception de votre système ?
- Dans quels autres scénarios échanger une précision parfaite contre la vitesse pourrait-il être bénéfique ?
- Comment l'utilisation des filtres de Bloom s'aligne-t-elle avec les SLA et les budgets d'erreur de votre système ?
Conclusion : La Fleur Est Tombée
Les filtres de Bloom ne sont peut-être pas la dernière nouveauté en ville, mais ce sont des outils éprouvés et robustes qui méritent une place dans votre boîte à outils backend. De la mise en cache à l'optimisation de la recherche, ces puissants probabilistes peuvent donner à vos systèmes distribués le coup de pouce en performance qu'ils désirent.
Alors, la prochaine fois que vous faites face à un déluge de données ou à un bourbier de requêtes, souvenez-vous : parfois, la solution est en fleur.
Maintenant, allez de l'avant et filtrez, vous magnifiques maestros du backend !