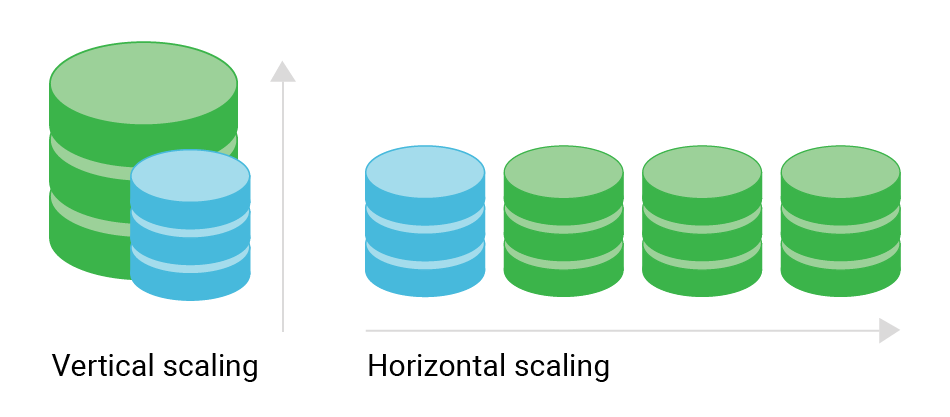
La mise à l'échelle ne consiste pas seulement à ajouter plus de matériel au problème (bien que cela puisse aider). Il s'agit de distribuer intelligemment vos données pour gérer une charge accrue, garantir une haute disponibilité et maintenir les performances. Voici notre duo dynamique : le sharding et la réplication.
Sharding : Découper votre pizza de données
Imaginez votre base de données comme une énorme pizza. Le sharding, c'est comme couper cette pizza en parts et les distribuer sur différentes assiettes (serveurs). Chaque part (shard) contient une portion de vos données, vous permettant de répartir la charge et d'améliorer les performances des requêtes.
Comment fonctionne le sharding ?
À la base, le sharding implique de partitionner vos données selon certains critères. Cela pourrait être :
- Basé sur des plages : Diviser les données par plages de valeurs (par exemple, utilisateurs A-M sur un shard, N-Z sur un autre)
- Basé sur le hachage : Utiliser une fonction de hachage pour déterminer à quel shard appartiennent les données
- Basé sur la géographie : Stocker les données sur les shards les plus proches des utilisateurs qui y accèdent
Voici un exemple simple de la façon dont vous pourriez implémenter le sharding basé sur des plages dans un scénario hypothétique :
def get_shard(user_id):
if user_id < 1000000:
return "shard_1"
elif user_id < 2000000:
return "shard_2"
else:
return "shard_3"
# Utilisation
user_data = get_user_data(user_id)
shard = get_shard(user_id)
save_to_database(shard, user_data)
Les avantages et inconvénients du sharding
Le sharding n'est pas toujours simple. Décomposons cela :
Avantages :
- Amélioration des performances des requêtes
- Évolutivité horizontale
- Réduction de la taille de l'index par shard
Inconvénients :
- Complexité accrue dans la logique de l'application
- Risque de déséquilibre dans la distribution des données
- Défis avec les opérations inter-shards
"Le sharding, c'est comme jongler avec des tronçonneuses. C'est impressionnant quand c'est bien fait, mais une erreur et tout devient compliqué." - DBA anonyme
Réplication : L'art du clonage de données
Si le sharding consiste à diviser pour mieux régner, la réplication repose sur l'adage : "deux têtes valent mieux qu'une". La réplication implique de créer des copies de vos données sur plusieurs nœuds, offrant redondance et améliorant les performances de lecture.
Architectures de réplication
Il existe deux principales architectures de réplication :
1. Réplication maître-esclave
Dans cette configuration, un nœud (le maître) gère les écritures, tandis que plusieurs nœuds esclaves gèrent les lectures. C'est comme avoir un chef (maître) qui prépare les repas, avec plusieurs serveurs (esclaves) qui les servent aux clients.
2. Réplication maître-maître
Ici, plusieurs nœuds peuvent gérer à la fois les lectures et les écritures. C'est comme avoir plusieurs chefs, chacun capable de préparer et de servir des repas.
Voici une représentation simplifiée en pseudo-code de la façon dont vous pourriez implémenter la réplication maître-esclave :
class Database:
def __init__(self, is_master=False):
self.is_master = is_master
self.data = {}
self.slaves = []
def write(self, key, value):
if self.is_master:
self.data[key] = value
for slave in self.slaves:
slave.replicate(key, value)
else:
raise Exception("Cannot write to slave")
def read(self, key):
return self.data.get(key)
def replicate(self, key, value):
self.data[key] = value
# Utilisation
master = Database(is_master=True)
slave1 = Database()
slave2 = Database()
master.slaves = [slave1, slave2]
master.write("user_1", {"name": "Alice", "age": 30})
print(slave1.read("user_1")) # Output: {"name": "Alice", "age": 30}
Réplication : Les avantages et les inconvénients
Avantages :
- Amélioration des performances de lecture
- Haute disponibilité et tolérance aux pannes
- Distribution géographique des données
Inconvénients :
- Risque d'incohérence des données
- Augmentation des besoins en stockage
- Complexité dans la gestion de plusieurs nœuds
Sharding vs Réplication : Le duel ultime ?
Pas vraiment. En fait, le sharding et la réplication fonctionnent souvent mieux ensemble. Pensez-y comme un match en équipe où le sharding s'occupe de la répartition des données, tandis que la réplication garantit que votre système reste opérationnel même lorsque des nœuds individuels tombent en panne.
Voici une matrice de décision rapide pour vous aider à choisir :
| Cas d'utilisation | Sharding | Réplication |
|---|---|---|
| Améliorer les performances d'écriture | ✅ | ❌ |
| Améliorer les performances de lecture | ✅ | ✅ |
| Haute disponibilité | ❌ | ✅ |
| Redondance des données | ❌ | ✅ |
Le théorème CAP : Choisissez-en deux, vous devez
Lors de la mise à l'échelle des bases de données, vous rencontrerez inévitablement le théorème CAP. Il stipule que dans un système distribué, vous ne pouvez avoir que deux des trois : Cohérence, Disponibilité et Tolérance aux partitions. Cela conduit à des compromis intéressants :
- Systèmes CA : Priorisent la cohérence et la disponibilité mais ne peuvent pas gérer les partitions réseau
- Systèmes CP : Maintiennent la cohérence et la tolérance aux partitions mais peuvent sacrifier la disponibilité
- Systèmes AP : Se concentrent sur la disponibilité et la tolérance aux partitions, potentiellement au détriment de la cohérence
La plupart des bases de données distribuées modernes appartiennent aux catégories CP ou AP, avec diverses stratégies pour atténuer les inconvénients de leur choix.
Implémentation du sharding et de la réplication dans les bases de données populaires
Faisons un tour rapide de la façon dont certaines bases de données populaires gèrent le sharding et la réplication :
MongoDB
MongoDB prend en charge à la fois le sharding et la réplication dès le départ. Il utilise une clé de shard pour distribuer les données sur plusieurs shards et fournit des ensembles de répliques pour une haute disponibilité.
// Activer le sharding pour une base de données
sh.enableSharding("mydb")
// Sharder une collection
sh.shardCollection("mydb.users", { "user_id": "hashed" })
// Créer un ensemble de répliques
rs.initiate({
_id: "myReplicaSet",
members: [
{ _id: 0, host: "mongodb0.example.net:27017" },
{ _id: 1, host: "mongodb1.example.net:27017" },
{ _id: 2, host: "mongodb2.example.net:27017" }
]
})
PostgreSQL
PostgreSQL n'a pas de sharding intégré mais le prend en charge via des extensions comme Citus. Cependant, il dispose de fonctionnalités de réplication robustes.
-- Configurer la réplication en streaming
ALTER SYSTEM SET wal_level = replica;
ALTER SYSTEM SET max_wal_senders = 10;
ALTER SYSTEM SET max_replication_slots = 10;
-- Sur le serveur de secours
CREATE SUBSCRIPTION my_subscription
CONNECTION 'host=primary_host port=5432 dbname=mydb'
PUBLICATION my_publication;
MySQL
MySQL offre à la fois des capacités de sharding (via MySQL Cluster) et de réplication.
-- Configurer la réplication maître-esclave
-- Sur le maître
CREATE USER 'repl'@'%' IDENTIFIED BY 'password';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
-- Sur l'esclave
CHANGE MASTER TO
MASTER_HOST='master_host_name',
MASTER_USER='repl',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=73;
START SLAVE;
Meilleures pratiques pour la mise à l'échelle de votre base de données
Alors que nous terminons notre voyage à travers le monde de la mise à l'échelle des bases de données, voici quelques règles d'or à garder à l'esprit :
- Planifiez à l'avance : Concevez votre schéma et votre application en pensant à l'évolutivité dès le départ.
- Surveillez et analysez : Vérifiez régulièrement les performances de votre base de données et identifiez les goulots d'étranglement.
- Commencez simplement : Commencez par une mise à l'échelle verticale et optimisez les requêtes avant de passer au sharding.
- Choisissez judicieusement votre clé de shard : Une mauvaise clé de shard peut entraîner une distribution inégale des données et des points chauds.
- Testez, testez, testez : Testez toujours soigneusement votre stratégie de mise à l'échelle dans un environnement de préproduction avant la production.
- Envisagez des services gérés : Les fournisseurs de cloud offrent des services de base de données gérés qui peuvent gérer une grande partie de la complexité de la mise à l'échelle pour vous.
Conclusion : Atteindre de nouveaux sommets
La mise à l'échelle des bases de données est autant un art qu'une science. Bien que le sharding et la réplication soient des outils puissants dans votre arsenal de mise à l'échelle, ils ne sont pas des solutions miracles. Chaque approche a ses propres défis et compromis.
Rappelez-vous, l'objectif n'est pas seulement de gérer plus de données ou d'utilisateurs ; c'est de le faire tout en maintenant les performances, la fiabilité et l'intégrité des données. Alors que vous vous lancez dans votre voyage de mise à l'échelle, continuez à apprendre, restez curieux et n'ayez pas peur d'expérimenter.
Maintenant, allez de l'avant et mettez à l'échelle ces bases de données ! Vos utilisateurs (et votre futur vous) vous en remercieront.
"La seule chose qui évolue avec la complexité, c'est la simplicité." - Inconnu
Avez-vous des histoires de guerre ou des conseils sur la mise à l'échelle des bases de données ? Partagez-les dans les commentaires ci-dessous. Apprenons des triomphes et des moments de facepalm de chacun !