Avant de commencer notre aventure de débogage, mettons les choses au clair :
La write amplification se produit lorsque la quantité de données écrites sur le support de stockage est supérieure à celle que l'application avait l'intention d'écrire.
En d'autres termes, votre base de données vous joue un tour en écrivant plus de données que vous ne l'avez demandé. Ce n'est pas seulement une question de gaspillage d'espace de stockage ; c'est un vampire de performance, qui épuise vos opérations d'E/S et use vos SSD plus vite qu'une paire de baskets lors d'un marathon.
Les Suspects Habituels : Cassandra et MongoDB
Enquêtons sur la manière dont la write amplification se manifeste dans deux bases de données NoSQL populaires :
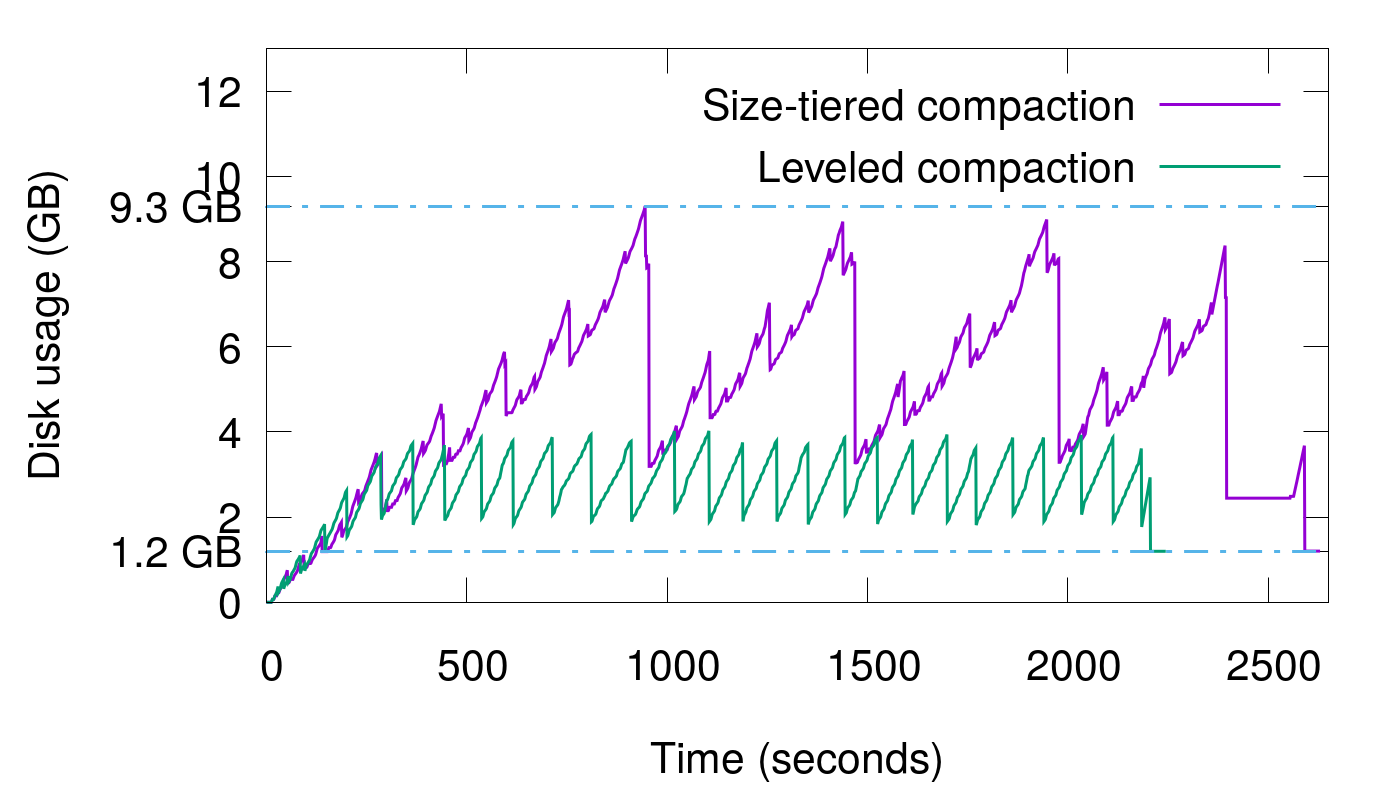
Cassandra : Le Dilemme de la Compaction
Cassandra, avec son moteur de stockage en arbre de fusion structuré par journal (LSM-tree), est particulièrement sujette à la write amplification. Voici pourquoi :
- SSTables immuables : Cassandra écrit des données dans des SSTables immuables, créant de nouveaux fichiers au lieu de modifier les existants.
- Compaction : Pour gérer ces fichiers, Cassandra effectue une compaction, fusionnant plusieurs SSTables en une seule.
- Tombstones : Les suppressions dans Cassandra créent des tombstones, qui sont... vous l'avez deviné, plus d'écritures !
Voyons un exemple simplifié de ce processus :
-- Écriture initiale
INSERT INTO users (id, name) VALUES (1, 'Alice');
-- Mise à jour (crée une nouvelle SSTable)
UPDATE users SET name = 'Alicia' WHERE id = 1;
-- Suppression (crée un tombstone)
DELETE FROM users WHERE id = 1;
Dans ce scénario, un seul enregistrement utilisateur pourrait être écrit plusieurs fois à travers différentes SSTables, entraînant une write amplification lors de la compaction.
MongoDB : Le Chaos de MMAP
MongoDB, surtout dans ses versions antérieures avec le moteur de stockage MMAP, avait ses propres problèmes de write amplification :
- Mises à jour sur place : MongoDB essaie de mettre à jour les documents sur place lorsque c'est possible.
- Croissance des documents : Si un document grandit et ne peut pas tenir dans son espace d'origine, il est réécrit à un nouvel emplacement.
- Fragmentation : Cela conduit à la fragmentation, nécessitant une compaction périodique.
Voici un exemple MongoDB qui pourrait entraîner une write amplification :
// Insertion initiale
db.users.insertOne({ _id: 1, name: "Bob", hobbies: ["lecture"] });
// Mise à jour qui fait croître le document
db.users.updateOne(
{ _id: 1 },
{ $push: { hobbies: "parachutisme" } }
);
Si "Bob" continue d'ajouter des hobbies, le document pourrait dépasser son espace alloué, obligeant MongoDB à le réécrire entièrement.
Débogage de la Write Amplification : Outils de Prédilection
Maintenant que nous savons à quoi nous avons affaire, armons-nous de quelques outils de débogage :
Pour Cassandra :
- nodetool cfstats : Cette commande fournit des statistiques sur les SSTables, y compris la write amplification.
- nodetool compactionstats : Vous donne des informations en temps réel sur les compactions en cours.
- Surveillance JMX : Utilisez des outils comme jconsole pour surveiller les métriques JMX de Cassandra liées à la compaction et aux SSTables.
Voici comment vous pourriez utiliser nodetool cfstats :
nodetool cfstats keyspace_name.table_name
Recherchez la métrique "Write amplification" dans la sortie.
Pour MongoDB :
- db.collection.stats() : Fournit des statistiques sur une collection, y compris avgObjSize et storageSize.
- mongostat : Un outil en ligne de commande qui montre des statistiques de performance de la base de données en temps réel.
- MongoDB Compass : Outil GUI qui fournit des aperçus visuels des performances de la base de données et de l'utilisation du stockage.
Voici un exemple d'utilisation de db.collection.stats() dans le shell MongoDB :
db.users.stats()
Faites attention au ratio entre "size" et "storageSize" pour évaluer la write amplification potentielle.
Domestiquer la Bête de la Write Amplification
Maintenant que nous avons identifié le problème, examinons quelques solutions :
Pour Cassandra :
- Ajuster les Stratégies de Compaction : Choisissez la bonne stratégie de compaction pour votre charge de travail (SizeTieredCompactionStrategy, LeveledCompactionStrategy, ou TimeWindowCompactionStrategy).
- Optimiser la Gestion des Tombstones : Ajustez gc_grace_seconds et utilisez des suppressions par lots lorsque c'est possible.
- Dimensionner Correctement les SSTables : Ajustez les paramètres compaction_throughput_mb_per_sec et max_threshold.
Voici un exemple de changement de stratégie de compaction :
ALTER TABLE users WITH compaction = {
'class': 'LeveledCompactionStrategy',
'sstable_size_in_mb': 160
};
Pour MongoDB :
- Utiliser le Moteur de Stockage WiredTiger : Il est plus efficace pour gérer la write amplification par rapport à MMAP.
- Implémenter la Pré-allocation de Documents : Si vous savez qu'un document va croître, pré-allouez de l'espace pour lui.
- Compaction Régulière : Exécutez la commande compact périodiquement pour récupérer de l'espace et réduire la fragmentation.
Exemple d'exécution de la compaction dans MongoDB :
db.runCommand( { compact: "users" } )
Le Coup de Théâtre : Quand la Write Amplification est en Réalité Bénéfique
Accrochez-vous à vos claviers, car voici où cela devient intéressant : parfois, la write amplification peut être bénéfique ! Dans certains scénarios, échanger des écritures supplémentaires pour de meilleures performances de lecture peut être une décision judicieuse.
Par exemple, dans Cassandra, la compaction réduit le nombre de SSTables à vérifier lors des lectures, ce qui peut accélérer les réponses aux requêtes. De même, la réécriture de documents dans MongoDB peut améliorer la localité des documents, ce qui peut améliorer les performances de lecture.
La clé est de trouver le bon équilibre pour votre cas d'utilisation spécifique. C'est comme choisir entre un couteau suisse et un outil spécialisé – parfois, la polyvalence vaut le poids supplémentaire.
Conclusion : Restez Calme et Continuez à Déboguer
La write amplification dans les bases de données NoSQL est comme ce bug étrange qui continue d'apparaître dans votre code – agaçant, mais surmontable avec la bonne approche. En comprenant les causes, en utilisant les bons outils de débogage et en mettant en œuvre des solutions ciblées, vous pouvez garder vos écritures de base de données sous contrôle et vos coûts de stockage à un niveau raisonnable.
Rappelez-vous, chaque base de données et charge de travail est unique. Ce qui fonctionne pour l'une peut ne pas fonctionner pour une autre. Continuez à expérimenter, mesurer et optimiser. Et qui sait ? Vous pourriez bien devenir le chuchoteur de la write amplification dans votre équipe.
Maintenant, allez-y et déboguez ces écritures sauvages ! Vos SSD vous remercieront.
"Le débogage, c'est comme être le détective dans un film policier où vous êtes aussi le meurtrier." - Filipe Fortes
Bon débogage !