La dégradation progressive consiste à maintenir votre système fonctionnel, même s'il n'est pas à 100 %. Nous explorerons des stratégies comme les disjoncteurs, la limitation de débit et la priorisation pour aider votre backend à résister à toutes les tempêtes. Accrochez-vous ; ça va être une balade mouvementée (mais éducative) !
Pourquoi s'embêter avec la dégradation progressive ?
Soyons réalistes : dans un monde idéal, nos systèmes fonctionneraient parfaitement 24h/24 et 7j/7. Mais nous vivons dans le monde réel, où la loi de Murphy est toujours à l'affût. La dégradation progressive est notre façon de défier Murphy en disant : "Bien essayé, mais nous avons prévu le coup."
Voici pourquoi c'est important :
- Maintient les fonctionnalités critiques en vie lorsque les choses se compliquent
- Empêche les défaillances en cascade qui peuvent faire tomber tout votre système
- Améliore l'expérience utilisateur pendant les périodes de stress intense
- Vous donne le temps de résoudre les problèmes sans crise majeure
Stratégies pour la dégradation progressive
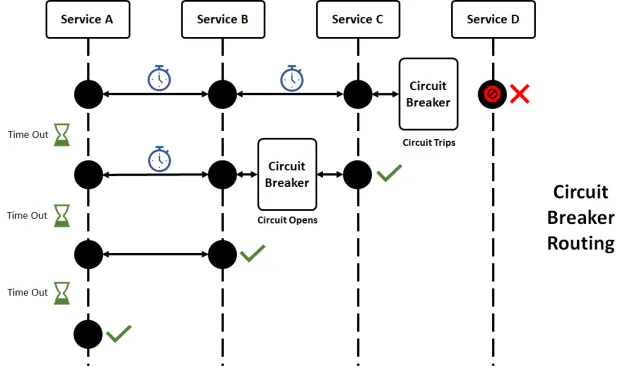
1. Disjoncteurs : Le tableau électrique de votre système
Vous vous souvenez avoir fait sauter un fusible quand vous étiez enfant en branchant trop de guirlandes de Noël ? Les disjoncteurs dans le logiciel fonctionnent de manière similaire, protégeant votre système de la surcharge.
Voici une implémentation simple utilisant la bibliothèque Hystrix :
public class ExampleCommand extends HystrixCommand {
private final String name;
public ExampleCommand(String name) {
super(HystrixCommandGroupKey.Factory.asKey("ExampleGroup"));
this.name = name;
}
@Override
protected String run() {
// Cela pourrait être un appel API ou une requête de base de données
return "Bonjour " + name + "!";
}
@Override
protected String getFallback() {
return "Bonjour Invité!";
}
}
Dans cet exemple, si la méthode run() échoue ou prend trop de temps, le disjoncteur s'active et appelle getFallback(). C'est comme avoir un générateur de secours pour votre code !
2. Limitation de débit : Apprendre les bonnes manières à votre API
La limitation de débit, c'est comme être videur dans un club. Vous ne voulez pas que trop de requêtes arrivent en même temps, sinon ça pourrait devenir chaotique. Voici comment vous pourriez l'implémenter avec Spring Boot et Bucket4j :
@RestController
public class ApiController {
private final Bucket bucket;
public ApiController() {
Bandwidth limit = Bandwidth.classic(20, Refill.greedy(20, Duration.ofMinutes(1)));
this.bucket = Bucket.builder()
.addLimit(limit)
.build();
}
@GetMapping("/api/resource")
public ResponseEntity getResource() {
if (bucket.tryConsume(1)) {
return ResponseEntity.ok("Voici votre ressource !");
}
return ResponseEntity.status(429).body("Trop de requêtes, veuillez réessayer plus tard.");
}
}
Cette configuration permet 20 requêtes par minute. Au-delà, on vous demande poliment de revenir plus tard. C'est comme si votre API avait appris à faire la queue !
3. Priorisation : Toutes les requêtes ne se valent pas
Quand les choses se compliquent, vous devez savoir quoi prioriser. C'est comme le triage aux urgences – les opérations critiques d'abord, les GIFs de chats plus tard (désolé, amateurs de chats).
Envisagez d'implémenter une file d'attente prioritaire pour vos requêtes :
public class PriorityRequestQueue {
private PriorityQueue queue;
public PriorityRequestQueue() {
this.queue = new PriorityQueue<>((r1, r2) -> r2.getPriority() - r1.getPriority());
}
public void addRequest(Request request) {
queue.offer(request);
}
public Request processNextRequest() {
return queue.poll();
}
}
Cela garantit que les requêtes de haute priorité (comme les paiements ou les actions utilisateur critiques) sont traitées en premier lorsque les ressources sont limitées.
L'art de l'échec gracieux
Maintenant que nous avons couvert quelques stratégies, parlons de l'art de l'échec gracieux. Il ne s'agit pas seulement d'éviter un effondrement total ; il s'agit de maintenir sa dignité face à l'adversité. Voici quelques conseils :
- Communication claire : Lors de la dégradation des services, soyez transparent avec vos utilisateurs. Un simple "Nous connaissons une forte demande, certaines fonctionnalités peuvent être temporairement indisponibles" est très utile.
- Dégradation progressive : Ne passez pas de 100 à 0. Désactivez d'abord les fonctionnalités non critiques, en gardant la fonctionnalité principale intacte aussi longtemps que possible.
- Reprises intelligentes : Implémentez un backoff exponentiel pour les reprises afin d'éviter de surcharger des services déjà stressés.
- Stratégies de mise en cache : Utilisez le cache judicieusement pour réduire la charge sur les services backend pendant les périodes de pointe.
Surveillance : Votre système d'alerte précoce
Mettre en œuvre des stratégies de dégradation progressive, c'est bien, mais comment savoir quand les déclencher ? Entrez la surveillance – le système d'alerte précoce de votre système.
Envisagez d'utiliser des outils comme Prometheus et Grafana pour surveiller les indicateurs clés :
- Temps de réponse
- Taux d'erreur
- Utilisation du CPU et de la mémoire
- Longueur des files d'attente
Configurez des alertes qui se déclenchent non seulement lorsque les choses vont mal, mais aussi lorsqu'elles commencent à sembler un peu douteuses. C'est comme avoir une prévision météo pour votre système – vous voulez connaître la tempête avant qu'elle n'arrive.
Tester vos stratégies de dégradation
Vous ne déploieriez pas de code sans le tester, n'est-ce pas ? (N'est-ce pas ?!) Il en va de même pour vos stratégies de dégradation. Entrez dans l'ingénierie du chaos – l'art de casser les choses exprès.
Des outils comme Chaos Monkey peuvent vous aider à simuler des pannes et des scénarios de forte charge dans un environnement contrôlé. C'est comme un exercice d'incendie pour votre système. Certes, cela peut être un peu stressant, mais il vaut mieux découvrir que vos sprinklers ne fonctionnent pas lors d'un exercice que lors d'un véritable incendie.
Exemple réel : L'approche de Netflix
Jetons un coup d'œil rapide à la façon dont le géant du streaming Netflix gère la dégradation progressive. Ils utilisent une technique appelée "repli par priorité". Voici une version simplifiée de leur approche :
- Essayez d'obtenir des recommandations personnalisées pour un utilisateur.
- Si cela échoue, revenez aux titres populaires pour leur région.
- Si les données régionales ne sont pas disponibles, affichez les titres populaires au niveau mondial.
- En dernier recours, affichez une liste de titres prédéfinie et statique.
Cela garantit que les utilisateurs voient toujours quelque chose, même si ce n'est pas l'expérience personnalisée idéale. C'est un excellent exemple de dégradation des fonctionnalités tout en fournissant de la valeur.
Conclusion : Embrasser le chaos
Concevoir pour la dégradation progressive ne consiste pas seulement à gérer les échecs ; il s'agit d'embrasser la nature chaotique des systèmes distribués. C'est accepter que les choses vont mal tourner et s'y préparer. C'est la différence entre dire "Oups, notre faute !" et "Nous avons la situation sous contrôle."
Rappelez-vous :
- Implémentez des disjoncteurs pour éviter les défaillances en cascade
- Utilisez la limitation de débit pour gérer les scénarios de forte charge
- Priorisez les opérations critiques lorsque les ressources sont limitées
- Communiquez clairement avec les utilisateurs pendant les états dégradés
- Surveillez, testez et améliorez continuellement vos stratégies de dégradation
En suivant ces stratégies, vous ne construisez pas seulement un système ; vous construisez un guerrier résilient et éprouvé, prêt à affronter tout le chaos que le monde numérique lui réserve. Maintenant, allez-y et dégradez-vous avec grâce !
"Le véritable test d'un système n'est pas sa performance lorsque tout va bien, mais son comportement lorsque tout va mal." - Philosophe DevOps Anonyme
Avez-vous des histoires de guerre sur la dégradation progressive dans vos systèmes ? Partagez-les dans les commentaires ! Après tout, le cauchemar d'un développeur est l'opportunité d'apprentissage d'un autre. Bon codage, et que vos systèmes se dégradent toujours avec grâce et style !