Les moyennes de charge sous Linux sont comme les signes vitaux de votre système - elles vous donnent un aperçu rapide de son état de santé. Mais contrairement à ce tracker de fitness à votre poignet, ces chiffres sont bien plus complexes.
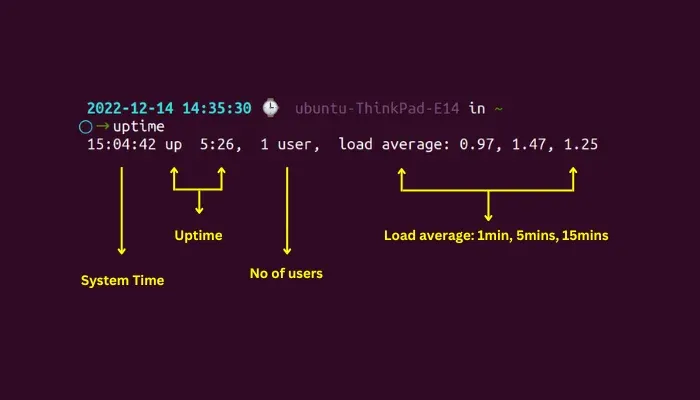
Lorsque vous exécutez la commande uptime, vous verrez quelque chose comme ceci :
$ uptime
15:23:52 up 21 days, 7:29, 1 user, load average: 0.15, 0.34, 0.36
Ces trois chiffres à la fin ? C'est notre sainte trinité des moyennes de charge, représentant la charge du système au cours des 1, 5 et 15 dernières minutes, respectivement. Mais que signifient-ils réellement ?
Décryptage des Chiffres
Voici le hic : les moyennes de charge ne concernent pas seulement l'utilisation du CPU. Elles sont un cocktail complexe de :
- Processus s'exécutant activement sur le CPU
- Processus en attente de temps CPU
- Processus en attente d'I/O (disque, réseau, etc.)
En essence, elles représentent le nombre moyen de processus qui sont soit en cours d'exécution, soit en attente d'exécution. Une moyenne de charge de 1.0 sur un système à un seul cœur signifie qu'il est à pleine capacité. Mais sur une machine à quatre cœurs ? Ce n'est qu'un quart de son potentiel.
Les Mathématiques Derrière la Magie
Sans plonger dans le calcul intégral (de rien), voici une vue simplifiée de la façon dont les moyennes de charge sont calculées :
- Le noyau suit le nombre de processus dans un état exécutable.
- Ce nombre est échantillonné toutes les quelques millisecondes.
- Une moyenne mobile exponentielle est calculée sur des intervalles de 1, 5 et 15 minutes.
C'est comme une moyenne glissante, mais avec plus de poids donné aux valeurs récentes. Cela signifie que les pics soudains apparaîtront rapidement dans la moyenne sur 1 minute mais s'atténueront dans la moyenne sur 15 minutes.
Interpréter les Runes
Maintenant, la question à un million de dollars : que nous disent réellement ces chiffres ? Voici un petit guide :
- En dessous de 1.0 : Votre système se tourne les pouces.
- À 1.0 : Vous êtes à pleine capacité (sur un système à un seul cœur).
- Au-dessus de 1.0 : Les processus attendent leur tour.
- Bien au-dessus de 1.0 : Houston, nous avons peut-être un problème.
Mais rappelez-vous, le contexte est roi ! Sur un serveur à 16 cœurs, une charge de 16.0 peut être parfaitement normale. Tout est relatif.
Outils de Travail
Bien que uptime soit idéal pour un aperçu rapide, il existe de meilleurs outils pour aller plus loin :
topouhtop: Vue en temps réel des processus systèmevmstat: Statistiques détaillées du systèmesar: Rapport d'activité système pour les données historiques
Pour les amateurs de GUI, des outils comme Grafana ou Netdata peuvent transformer ces chiffres en visualisations belles et exploitables.
Quand une Charge Élevée n'est pas une Alerte Rouge
Voici un retournement de situation : des moyennes de charge élevées ne sont pas toujours mauvaises. Parfois, elles sont simplement le signe que votre système fait son travail. Considérez ces scénarios :
- Un travail de compilation saturant vos CPU
- Un processus de sauvegarde causant une forte I/O
- Un pic soudain de trafic web
La clé est de corréler les moyennes de charge avec d'autres métriques. L'utilisation du CPU est-elle élevée ? L'I/O du disque est-elle à son maximum ? Le réseau est-il saturé ? Le contexte est tout.
Dépannage : Quand les Chiffres Attaquent
Si vos moyennes de charge sont constamment élevées et que vous êtes sûr que ce n'est pas juste votre système qui se montre, il est temps de jouer au détective. Voici un guide étape par étape :
- Utilisez
toppour identifier les processus gourmands en CPU - Vérifiez les temps d'attente I/O avec
iostat - Cherchez des problèmes de mémoire avec
freeetvmstat - Analysez les goulots d'étranglement réseau avec
netstatouiftop
Rappelez-vous, une charge élevée peut être causée par un seul processus défaillant ou une tempête parfaite de petits problèmes.
Le Dilemme Multi-Cœur
À l'ère des processeurs multi-cœurs, interpréter les moyennes de charge devient plus compliqué. Une charge de 4.0 sur un système à quatre cœurs est effectivement la même que 1.0 sur une machine à un seul cœur. Pour normaliser votre moyenne de charge, divisez-la par le nombre de cœurs.
Voici un petit extrait Python pour vous aider :
import os
def normalized_load():
cores = os.cpu_count()
load1, load5, load15 = os.getloadavg()
return [load1/cores, load5/cores, load15/cores]
print(normalized_load())
Bonnes Pratiques : Garder Votre Système sous Contrôle
Mieux vaut prévenir que guérir, n'est-ce pas ? Voici quelques conseils pour garder vos moyennes de charge sous contrôle :
- Mettez en place une surveillance et des alertes (Nagios, Zabbix ou Prometheus sont d'excellentes options)
- Utilisez
niceetionicepour prioriser les processus - Implémentez des limites de ressources appropriées avec
ulimitou cgroups - Examinez et optimisez régulièrement vos applications les plus gourmandes en ressources
Démystification : Édition Moyenne de Charge
Clarifions quelques idées reçues :
- Mythe : La moyenne de charge est juste l'utilisation du CPU.
Vérité : Elle inclut les processus en attente de CPU, d'I/O et d'autres ressources. - Mythe : Une moyenne de charge élevée signifie toujours des problèmes.
Vérité : Cela dépend de la capacité de votre système et de la nature de la charge de travail. - Mythe : Les moyennes de charge sont précises à trois décimales.
Vérité : Ce sont des approximations et ne doivent pas être traitées comme des valeurs exactes.
Scénarios Réels
Examinons quelques scénarios réels pour mettre tout cela en perspective :
Scénario 1 : Les Malheurs du Serveur Web
Imaginez que vous gérez un serveur web et que vous remarquez que les moyennes de charge augmentent. Voici comment vous pourriez aborder la situation :
- Vérifiez les journaux du serveur web pour un pic de trafic
- Utilisez
toppour voir si les processus du serveur web sont limités par le CPU - Vérifiez
iostatpour tout goulot d'étranglement I/O (peut-être des requêtes de base de données lentes ?) - Examinez
netstatpour des problèmes liés au réseau
La solution pourrait être aussi simple que d'optimiser quelques requêtes de base de données ou aussi complexe que de faire évoluer votre infrastructure.
Scénario 2 : La Sauvegarde Incontrôlée
Vous remarquez des moyennes de charge élevées pendant les heures creuses. Après quelques recherches, vous trouvez :
- Les temps d'attente I/O sont à leur maximum
- Un processus de sauvegarde martèle le disque
- L'utilisation du CPU est relativement faible
La solution ? Peut-être ajuster le calendrier de sauvegarde, utiliser des sauvegardes incrémentielles ou passer à des SSD pourrait aider.
Conclusion : Le Bilan des Moyennes de Charge
Et voilà, mesdames et messieurs ! Nous avons démystifié ces trois chiffres énigmatiques qui vous narguaient depuis votre terminal. Rappelez-vous, les moyennes de charge sont des indicateurs puissants, mais elles ne sont qu'une pièce du puzzle. Corrélez-les toujours avec d'autres métriques pour avoir une vue complète de la santé de votre système.
La prochaine fois que vous verrez ces chiffres grimper, vous saurez exactement ce qu'ils signifient et comment les aborder. Maintenant, allez conquérir ces serveurs !
"La moyenne de charge n'est pas toute l'histoire, mais c'est souvent là que l'histoire commence." - Tout administrateur système Linux, probablement
Pour Aller Plus Loin
- Documentation du noyau Linux sur /proc
- Source du noyau Linux : loadavg.c
- Analyse approfondie de Brendan Gregg sur les moyennes de charge
Bon équilibrage de charge, et que vos moyennes soient toujours basses et votre disponibilité élevée !