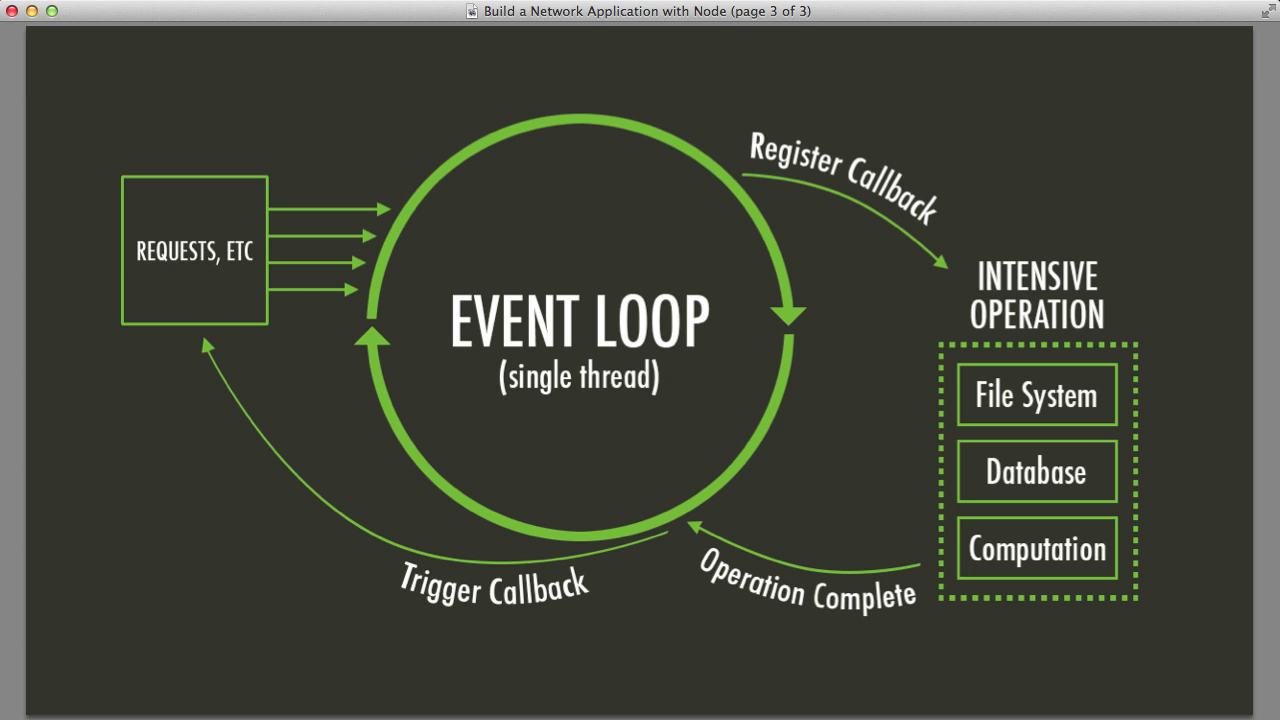
La boucle d'événements est le cœur de Node.js, propulsant les opérations asynchrones à travers votre application comme le sang dans les veines. Elle est monothread, ce qui signifie qu'elle peut gérer une opération à la fois. Mais ne vous y trompez pas – elle est incroyablement rapide et efficace.
Voici une vue simplifiée de son fonctionnement :
- Exécuter le code synchrone
- Traiter les minuteries (setTimeout, setInterval)
- Traiter les callbacks d'E/S
- Traiter les callbacks setImmediate()
- Fermer les callbacks
- Répéter le processus
Ça a l'air simple, non ? Eh bien, les choses peuvent se compliquer lorsque vous commencez à empiler des opérations complexes. C'est là que nos modèles avancés deviennent utiles.
Modèle 1 : Threads de travail - La folie du multithreading
Vous vous souvenez quand j'ai dit que Node.js est monothread ? Eh bien, ce n'est pas toute la vérité. Voici les Threads de travail – la réponse de Node.js aux tâches intensives en CPU qui bloqueraient autrement notre précieuse boucle d'événements.
Voici un exemple rapide d'utilisation des threads de travail :
const { Worker, isMainThread, parentPort } = require('worker_threads');
if (isMainThread) {
const worker = new Worker(__filename);
worker.on('message', (message) => {
console.log('Reçu :', message);
});
worker.postMessage('Bonjour, Worker!');
} else {
parentPort.on('message', (message) => {
console.log('Worker a reçu :', message);
parentPort.postMessage('Bonjour, thread principal!');
});
}
Ce code crée un thread de travail qui peut s'exécuter en parallèle avec le thread principal, vous permettant de déléguer des calculs lourds sans bloquer la boucle d'événements. C'est comme avoir un assistant personnel pour vos tâches intensives en CPU !
Quand utiliser les Threads de travail
- Opérations liées au CPU (calculs complexes, traitement de données)
- Exécution parallèle de tâches indépendantes
- Amélioration des performances des opérations synchrones
Conseil pro : Ne vous emballez pas avec les threads de travail ! Ils ont un coût, alors utilisez-les judicieusement pour les tâches qui bénéficient vraiment de la parallélisation.
Modèle 2 : Clustering - Parce que deux têtes valent mieux qu'une
Qu'est-ce qui est mieux qu'un processus Node.js ? Plusieurs processus Node.js ! C'est l'idée derrière le clustering. Il vous permet de créer des processus enfants qui partagent les ports du serveur, distribuant efficacement la charge de travail sur plusieurs cœurs CPU.
Voici un exemple simple de clustering :
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} est en cours d'exécution`);
// Créer des workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} est mort`);
});
} else {
// Les workers peuvent partager n'importe quelle connexion TCP
// Dans ce cas, c'est un serveur HTTP
http.createServer((req, res) => {
res.writeHead(200);
res.end('Bonjour le monde\n');
}).listen(8000);
console.log(`Worker ${process.pid} a démarré`);
}
Ce code crée plusieurs processus de travail, chacun capable de gérer des requêtes HTTP. C'est comme cloner votre serveur et avoir une armée de mini-serveurs prêts à gérer les requêtes entrantes !
Avantages du Clustering
- Amélioration des performances et du débit
- Meilleure utilisation des systèmes multi-cœurs
- Fiabilité accrue (si un worker plante, les autres peuvent prendre le relais)
Rappelez-vous : Avec un grand pouvoir vient une grande responsabilité. Le clustering peut augmenter considérablement la complexité de votre application, alors utilisez-le lorsque vous avez vraiment besoin de vous étendre horizontalement.
Modèle 3 : Itérateurs asynchrones - Dompter la bête des flux de données
Gérer de grands ensembles de données ou des flux dans Node.js peut être comme essayer de boire à un tuyau d'incendie. Les itérateurs asynchrones viennent à la rescousse, vous permettant de traiter les données morceau par morceau sans surcharger votre boucle d'événements.
Voyons un exemple :
const { createReadStream } = require('fs');
const { createInterface } = require('readline');
async function* processFileLines(filename) {
const rl = createInterface({
input: createReadStream(filename),
crlfDelay: Infinity
});
for await (const line of rl) {
yield line;
}
}
(async () => {
for await (const line of processFileLines('huge_file.txt')) {
console.log('Traité :', line);
// Faire quelque chose avec chaque ligne
}
})();
Ce code lit un fichier potentiellement énorme ligne par ligne, vous permettant de traiter chaque ligne sans charger le fichier entier en mémoire. C'est comme avoir un tapis roulant pour vos données, vous les fournissant à un rythme gérable !
Pourquoi les Itérateurs Asynchrones sont géniaux
- Utilisation efficace de la mémoire pour les grands ensembles de données
- Moyen naturel de gérer les flux de données asynchrones
- Lisibilité améliorée pour les pipelines de traitement de données complexes
Tout assembler : Un scénario réel
Imaginons que nous construisons un système d'analyse de journaux qui doit traiter des fichiers de journaux massifs, effectuer des calculs intensifs en CPU et servir les résultats via une API. Voici comment nous pourrions combiner ces modèles :
const cluster = require('cluster');
const { Worker } = require('worker_threads');
const express = require('express');
const { processFileLines } = require('./fileProcessor');
if (cluster.isMaster) {
console.log(`Master ${process.pid} est en cours d'exécution`);
// Créer des workers pour le serveur API
for (let i = 0; i < 2; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} est mort`);
});
} else {
const app = express();
app.get('/analyze', async (req, res) => {
const results = [];
const worker = new Worker('./analyzeWorker.js');
for await (const line of processFileLines('huge_log_file.txt')) {
worker.postMessage(line);
}
worker.on('message', (result) => {
results.push(result);
});
worker.on('exit', () => {
res.json(results);
});
});
app.listen(3000, () => console.log(`Worker ${process.pid} a démarré`));
}
Dans cet exemple, nous utilisons :
- Le clustering pour créer plusieurs processus de serveur API
- Les threads de travail pour déléguer l'analyse de journaux intensifs en CPU
- Les itérateurs asynchrones pour traiter efficacement de grands fichiers de journaux
Cette combinaison nous permet de gérer plusieurs requêtes simultanées, de traiter de grands fichiers efficacement et d'effectuer des calculs complexes sans bloquer la boucle d'événements. C'est comme avoir une machine bien huilée où chaque partie connaît son rôle et travaille en harmonie avec les autres !
Conclusion : Leçons apprises
Comme nous l'avons vu, gérer la concurrence dans Node.js consiste à comprendre la boucle d'événements et à savoir quand utiliser des modèles avancés. Voici les points clés à retenir :
- Utilisez les threads de travail pour les tâches intensives en CPU qui bloqueraient la boucle d'événements
- Implémentez le clustering pour tirer parti des systèmes multi-cœurs et améliorer l'évolutivité
- Exploitez les itérateurs asynchrones pour un traitement efficace des grands ensembles de données ou des flux
- Combinez ces modèles stratégiquement en fonction de votre cas d'utilisation spécifique
Rappelez-vous, avec un grand pouvoir vient une grande... complexité. Ces modèles sont des outils puissants, mais ils introduisent également de nouveaux défis en termes de débogage, de gestion d'état et d'architecture globale de l'application. Utilisez-les judicieusement, et profilez toujours votre application pour vous assurer que vous tirez réellement des avantages de ces techniques avancées.
Réflexions
Alors que vous plongez plus profondément dans le monde de la concurrence Node.js, voici quelques questions à méditer :
- Comment ces modèles pourraient-ils affecter la gestion des erreurs et la résilience de votre application ?
- Quels sont les compromis entre l'utilisation des threads de travail et la création de processus séparés ?
- Comment pouvez-vous surveiller et déboguer efficacement les applications qui utilisent ces modèles de concurrence avancés ?
Le chemin vers la maîtrise de la concurrence dans Node.js est en cours, mais armé de ces modèles, vous êtes bien parti pour construire des applications ultra-rapides, efficaces et évolutives. Maintenant, allez de l'avant et maîtrisez cette boucle d'événements !
Rappelez-vous : Le meilleur code n'est pas toujours le plus complexe. Parfois, une application monothread bien structurée peut surpasser une application multithread mal implémentée. Mesurez toujours, profilez et optimisez en fonction des données de performance réelles.
Bon codage, et que vos boucles d'événements ne soient jamais interrompues (sauf si vous le souhaitez) !