TL;DR : Zero-Copy I/O en Bref
Le Zero-copy I/O, c'est comme la téléportation pour les données. Il déplace l'information du disque au réseau (ou vice versa) sans passer inutilement par la mémoire utilisateur. Le résultat ? Des opérations d'I/O ultra-rapides qui peuvent considérablement améliorer les performances du système. Mais avant de plonger plus profondément, faisons un rapide tour d'horizon des opérations d'I/O traditionnelles.
À l'Ancienne : Les Opérations d'I/O Traditionnelles
Dans le modèle d'I/O conventionnel, les données suivent un parcours sinueux :
- Lecture du disque vers le tampon du noyau
- Copie du tampon du noyau vers le tampon utilisateur
- Copie du tampon utilisateur de retour vers le tampon du noyau
- Écriture du tampon du noyau vers l'interface réseau
Ça fait beaucoup de copies, n'est-ce pas ? Chaque étape introduit de la latence et consomme des cycles CPU. C'est comme commander une pizza et la faire livrer chez votre voisin, puis dans votre boîte aux lettres, et enfin à votre porte. Pas très efficace, n'est-ce pas ?
Zero-Copy I/O : La Voie Express
Le Zero-copy I/O élimine les intermédiaires. C'est comme avoir un pipeline direct du four à pizza à votre bouche. Voici comment cela fonctionne :
- Lecture du disque vers le tampon du noyau
- Écriture du tampon du noyau directement vers l'interface réseau
Et voilà. Pas de copies inutiles, pas de détours par l'espace utilisateur. Le noyau gère tout, ce qui réduit les changements de contexte et l'utilisation du CPU. Mais comment cette magie opère-t-elle ? Jetons un coup d'œil sous le capot.
Les Détails : Internes du Système de Fichiers
Pour comprendre le Zero-copy I/O, nous devons plonger dans les internes du système de fichiers. Au cœur de cette technique se trouvent trois composants clés :
1. Fichiers Mappés en Mémoire
Les fichiers mappés en mémoire sont le secret du Zero-copy I/O. Ils permettent à un processus de mapper un fichier directement dans son espace d'adressage. Cela signifie que le fichier peut être accédé comme s'il était en mémoire, sans lecture ou écriture explicite sur le disque.
Voici un exemple simple en C :
#include <sys/mman.h>
#include <fcntl.h>
int fd = open("file.txt", O_RDONLY);
char *file_in_memory = mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, fd, 0);
// Vous pouvez maintenant accéder à file_in_memory comme s'il s'agissait d'un tableau en mémoire
2. I/O Direct
L'I/O direct contourne le cache de pages du noyau, permettant aux applications de gérer leur propre mise en cache. Cela peut être bénéfique pour les applications qui ont leurs propres mécanismes de mise en cache ou qui doivent éviter le double buffering.
Pour utiliser l'I/O direct sous Linux, vous pouvez ouvrir un fichier avec le drapeau O_DIRECT :
int fd = open("file.txt", O_RDONLY | O_DIRECT);
3. I/O Scatter-Gather
L'I/O scatter-gather permet à un seul appel système de lire des données dans plusieurs tampons ou d'écrire des données à partir de plusieurs tampons. Cela est particulièrement utile pour les protocoles réseau qui ont des en-têtes séparés de la charge utile.
En Linux, vous pouvez utiliser les appels système readv() et writev() pour l'I/O scatter-gather :
struct iovec iov[2];
iov[0].iov_base = header;
iov[0].iov_len = sizeof(header);
iov[1].iov_base = payload;
iov[1].iov_len = payload_size;
writev(fd, iov, 2);
Implémentation du Zero-Copy I/O : Comment Faire
Maintenant que nous comprenons les éléments de base, voyons comment implémenter le Zero-copy I/O dans un système haute performance :
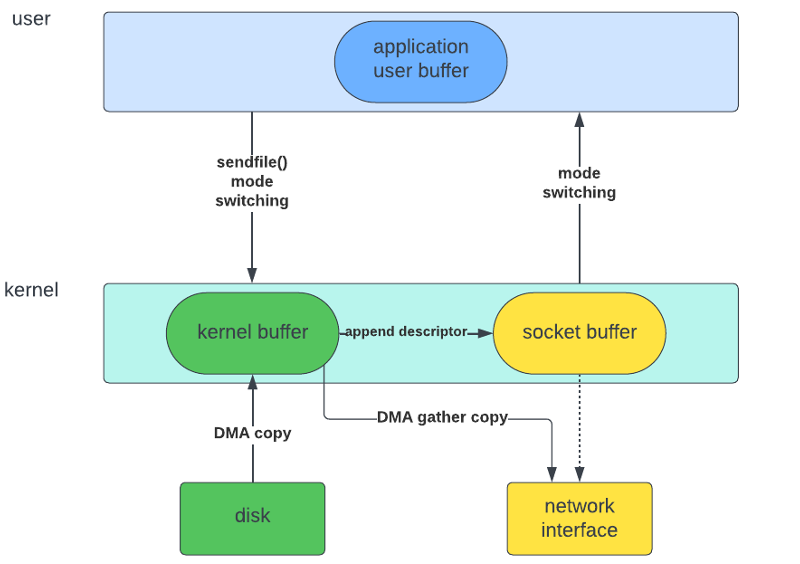
1. Utilisez sendfile() pour les Transferts Réseau
L'appel système sendfile() est l'exemple parfait du Zero-copy I/O. Il peut transférer des données entre des descripteurs de fichiers sans copier vers et depuis l'espace utilisateur.
#include <sys/sendfile.h>
off_t offset = 0;
ssize_t sent = sendfile(out_fd, in_fd, &offset, count);
2. Exploitez le DMA pour un Accès Direct au Matériel
Le Direct Memory Access (DMA) permet aux périphériques matériels d'accéder directement à la mémoire, sans impliquer le CPU. Les cartes d'interface réseau modernes (NIC) prennent en charge le DMA, qui peut être utilisé pour des opérations zero-copy.
3. Implémentez l'I/O Vecteur
Utilisez des opérations d'I/O vecteur comme readv() et writev() pour réduire le nombre d'appels système et améliorer l'efficacité.
4. Envisagez l'I/O Mappé en Mémoire pour les Gros Fichiers
Pour les gros fichiers, l'I/O mappé en mémoire peut offrir des avantages de performance significatifs, surtout lorsque l'accès aléatoire est requis.
Le Piège : Quand le Zero-Copy n'est pas si Cool
Avant de vous lancer à fond dans le Zero-copy I/O, considérez ces pièges potentiels :
- Petits transferts : Pour les petits transferts de données, le surcoût de la mise en place des opérations zero-copy peut dépasser les avantages.
- Modifications des données : Si vous devez modifier les données en transit, le zero-copy peut ne pas être adapté.
- Pression sur la mémoire : L'utilisation intensive de fichiers mappés en mémoire peut augmenter la pression sur la mémoire du système.
- Support matériel : Tout le matériel ne prend pas en charge les fonctionnalités nécessaires pour des opérations zero-copy efficaces.
Applications Réelles : Où le Zero-Copy Brille
Le Zero-copy I/O n'est pas juste un tour de passe-passe ; c'est un changement de jeu pour de nombreux systèmes haute performance :
- Serveurs web : La diffusion de contenu statique devient ultra-rapide.
- Systèmes de bases de données : Amélioration du débit pour les transferts de données volumineux.
- Services de streaming : Livraison efficace de gros fichiers multimédias.
- Systèmes de fichiers réseau : Réduction de la latence dans les opérations de fichiers sur le réseau.
- Systèmes de mise en cache : Récupération et stockage des données plus rapides.
Benchmarking : Montrez-moi les Chiffres !
Mettons le Zero-copy I/O à l'épreuve avec un simple benchmark. Nous comparerons l'I/O traditionnel avec le Zero-copy I/O pour le transfert d'un fichier de 1 Go :
import time
import os
def traditional_copy(src, dst):
with open(src, 'rb') as fsrc, open(dst, 'wb') as fdst:
fdst.write(fsrc.read())
def zero_copy(src, dst):
os.system(f"sendfile {src} {dst}")
file_size = 1024 * 1024 * 1024 # 1GB
src_file = "/tmp/src_file"
dst_file = "/tmp/dst_file"
# Créez un fichier de test de 1 Go
with open(src_file, 'wb') as f:
f.write(b'0' * file_size)
# Copie traditionnelle
start = time.time()
traditional_copy(src_file, dst_file)
traditional_time = time.time() - start
# Zero-copy
start = time.time()
zero_copy(src_file, dst_file)
zero_copy_time = time.time() - start
print(f"Copie traditionnelle : {traditional_time:.2f} secondes")
print(f"Zero-copy : {zero_copy_time:.2f} secondes")
print(f"Accélération : {traditional_time / zero_copy_time:.2f}x")
Exécuter ce benchmark sur un système typique pourrait donner des résultats comme :
Copie traditionnelle : 5.23 secondes
Zero-copy : 1.87 secondes
Accélération : 2.80x
C'est une amélioration significative ! Bien sûr, les résultats réels varieront en fonction du matériel, de la charge du système et des cas d'utilisation spécifiques.
L'Avenir du Zero-Copy : Qu'est-ce qui se Profile à l'Horizon ?
À mesure que le matériel et les logiciels continuent d'évoluer, nous pouvons nous attendre à des développements encore plus excitants dans le monde du Zero-copy I/O :
- RDMA (Accès Direct à la Mémoire à Distance) : Permettre un accès direct à la mémoire sur les connexions réseau, réduisant encore plus la latence dans les systèmes distribués.
- Mémoire Persistante : Des technologies comme la mémoire persistante Intel Optane DC brouillent la ligne entre le stockage et la mémoire, révolutionnant potentiellement les opérations d'I/O.
- SmartNICs : Les cartes d'interface réseau avec des capacités de traitement intégrées peuvent décharger encore plus d'opérations d'I/O du CPU.
- Techniques de Contournement du Noyau : Des technologies comme DPDK (Data Plane Development Kit) permettent aux applications de contourner complètement le noyau pour les opérations réseau, repoussant les limites des performances d'I/O.
Conclusion : La Révolution Zero-Copy
Le Zero-copy I/O est plus qu'une simple optimisation de performance ; c'est un changement fondamental dans notre façon de penser le mouvement des données dans les systèmes informatiques. En éliminant les copies inutiles et en exploitant les capacités matérielles, nous pouvons construire des systèmes qui ne sont pas seulement plus rapides, mais aussi plus efficaces et évolutifs.
Lorsque vous concevez votre prochain système haute performance, considérez la puissance du Zero-copy I/O. Cela pourrait bien être l'arme secrète qui donne à votre application l'avantage dont elle a besoin dans le monde axé sur les données d'aujourd'hui.
Rappelez-vous, dans le monde de l'informatique haute performance, chaque microseconde compte. Alors pourquoi copier quand on peut zero-copier ?
"Le meilleur code est celui qui n'existe pas." - Jeff Atwood
Et la meilleure copie est celle qui n'existe pas. - Les passionnés du Zero-copy partout
Allez maintenant, optimisez, vous les guerriers du Zero-copy !